
 Думаю, все знают, что такое сессии в Django, не так ли? Без них довольно сложно представить разработку приложений. В них обычно хранят ID пользователя и какие-нибудь промежуточные данные. Ими пользуются чаще, чем задумываются о настройке способа их хранения. Конечно, настроек «по умолчанию», как правило, бывает достаточно для того, чтобы запустить практически любой проект. Однако пытливый ум требует узнать, какая из возможных конфигураций работает быстрее…
Думаю, все знают, что такое сессии в Django, не так ли? Без них довольно сложно представить разработку приложений. В них обычно хранят ID пользователя и какие-нибудь промежуточные данные. Ими пользуются чаще, чем задумываются о настройке способа их хранения. Конечно, настроек «по умолчанию», как правило, бывает достаточно для того, чтобы запустить практически любой проект. Однако пытливый ум требует узнать, какая из возможных конфигураций работает быстрее…В документации Django очень подробно описывается, как работают различные Session Engine и как их настроить. В этой статье пойдёт речь о том, как я тестировал различные конфигурации развёртывания гипотетического проекта.
Исходные данные
Тестирование проводилось на 2-х виртуальных машинах под управлением debian wheezy. Машины расположены в рамках одной подсети.
- model name: Intel® Xeon® CPU E7- 4830 @ 2.13GHz
- RAM: 8GB
- Linux Kernel Version: 3.2.0-4-amd64
Первая — для сохранения данных сессии в базах данных. Вторая для запуска приложения.
В рамках тестирования использовалось 2 БД:
- PostgreSQL – 9.1.15
- Redis — 2.4.14-1
Приложение запущено на
- Python — 3.4.3
- Django — 1.7.7
Выбран сервер приложений gunicorn с асинхронными рабочими (eventlet):
- Gunicorn — 19.3.0
- Eventlet — 0.17.3
- libevent — 1.4-2
Для оценки производительности использовался Apache Bench.
- Число запросов = 4000
- Паралельных соединений = 20
- В рамках одного идентификатора сессии (sessionid)
Задача
Протестировать входящие в фреймворк бэкенды для хранения данных сессий
- database-backed — postgresql
- cached — redis
- file-based — файловая система ext2
- cookie-based — для данных до 4K
Документацию по ним можно найти тут.
Тестирование
Я решил провести тестирование в двух конфигурациях: «только чтение» и «чтение и запись». При этом также сформировать не очень сложную страничку с использованием django-темплейтов, чтобы это походило на хоть и очень простое, но всё же реальное приложение.
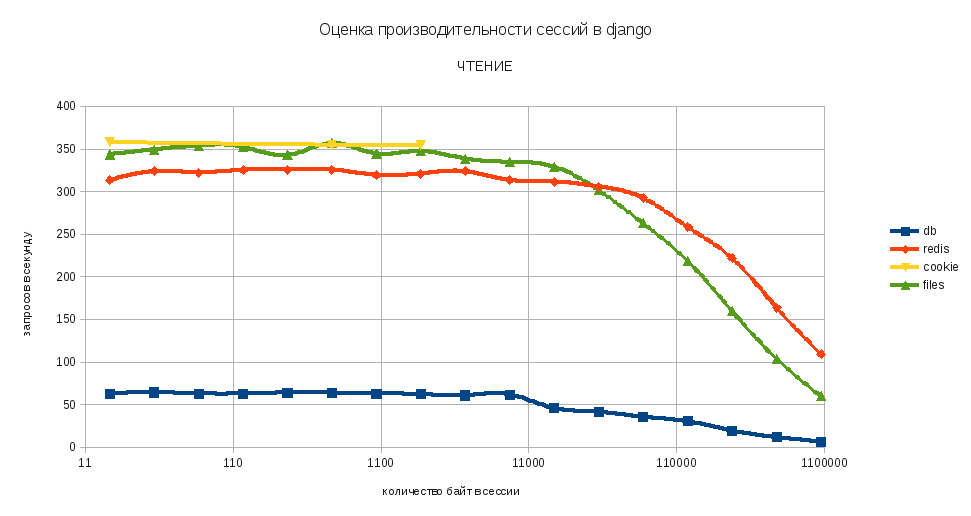
Чтение
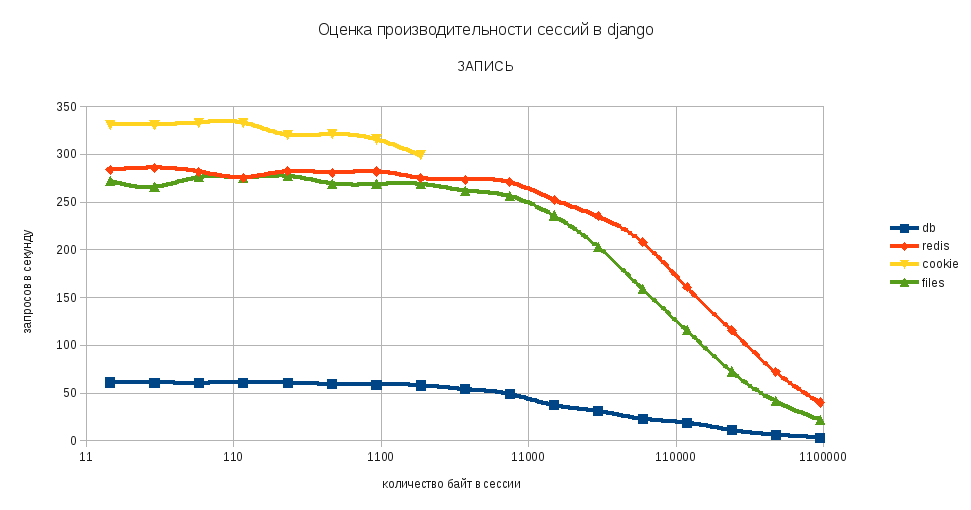
Запись
Выводы
Из графиков видно, что при хранении большого количества данных в сессии существенно падает скорость загрузки страниц приложения. Зависимость между количеством данных и скоростью загрузки приобретает логарифмический характер после 16К.
Также сложно не заменить, что сохранение сессии в базе данных существенно отстаёт по производительности от остальных конфигураций. Впрочем, это было довольно предсказуемо. Довольно необычным для меня было поведение файлового хранилища сессий. В частности, скорость доступа к файлу оказалась выше, чем у БД redis в рамках одной подсети при объёме сессии меньше ~ 64K. Возможно, это как-то связано с конфигурацией виртуальных машин, не знаю…
По результатам тестов сформировал следующие правила в использовании хранилищами:

Спасибо за внимание!
Комментарии (10)

un1t
23.04.2015 14:44+2Если тестировалось один sessionid то нет ничего удивительного, файл кешируется на уровне ОС и на уровне диска. Т.е. по факту все читалось из памяти. Что редис, что файл. Почему постгрес так тупил загадка.

mnach Автор
24.04.2015 07:04Да, на счёт файла вы меня просвятили… Получается тест этого бэкэнда был не совсем корректный.


mnach Автор
24.04.2015 07:04Настройки постгрес — дефолтные. Если есть у кого-нибудь ссылка на хорошее руководство по настройке этой базы данных, буду очень рад почитать!
И провести тестирование по новой.
dezconnect
Сравнить бы с Flask…
icCE
А я бы хотел нормальных тестов gunicorn vs uwsgi.
mnach Автор
Я вот тут смотрел: Benchmark uWSGI vs gunicorn for async workers
не знаю нормальные они нет…
mnach Автор
Как я понимаю во Flask встроен только один тип хранилищ сессий — зашифрованный в куки. Т.е. может применяться при небольшом размере сессии. Скорость работы мне кажется будет примерно такой-же как в django у signed_cookie, т.к. принцип действия очень похож.
Проблема такого тестирования для меня состоит в том, что для него надо исключить любые другие возможные влияния, как то: формирование страницы, различные middleware и прочее… Для такого тестирования наверное лучше вообще исключить сервер и не Apache Bench использовать, а какой-нибудь timeit…