

Исследователю-эпиграфисту не всегда достаётся идеальная каменная табличка с целой надписью. Чаще всего это фрагмент с выбитыми кусками, затёртыми словами и отсутствующими датами из которого нужно не только восстановить текст, но и понять, кто его оставил, где, когда и зачем.
Долгое время это была ручная работа: листать каталоги, сверять формулы, гадать, к какой провинции относился тот или иной странный титул. Теперь есть Aeneas — мультимодальная генеративная модель, которая берёт транскрипцию, отмечает лакуны и строит рабочие гипотезы: как мог выглядеть утраченный фрагмент, когда и где была создана надпись, с какими другими текстами она связана по смыслу.
{kind=link}
Римляне писали везде: на колоннах, алтарях, мраморных плитах, бронзовых табличках, стенах домов. Сообщения были публичными: «Император построил акведук», «Луций + Клавдия», «Здесь покоится гражданин, проживший столько‑то лет». Они не пересказаны летописцами, а потому дают увидеть язык эпохи со всеми сокращениями, орфографическими странностями и архаизмами.
Каждая надпись — кусочек пазла.
Одна сообщает имя легионера из Могонтиацума, другая — какой храм отстроили после пожара, третья — какого сенатора благодарили за игры. Если сложить их правильно, то получится картина общества, где политика, религия и быт переплетаются на уровне конкретных имён и событий.
В латинской эпиграфике экономили каждую букву и любили аббревиатуры: например, Imperator Caesar Augustus Pater Patriae можно сократить до IMP CAES AVG P P. Отдельный квест — даты. Во-первых, их часто нет. Во-вторых, когда они есть, то всё равно с ними сложно. Римляне называли годы именами консулов из официальных списков (fasti consulares). Поэтому в надписях встречаются формулы вроде Marco Crasso et Gnaeo Pompeio consulibus — «когда консулами были Марк Красс и Гней Помпей». Чтобы понять, какой это год, нужно сверяться со списками. Сами плиты переиспользовали, кололи на стройматериалы, и иногда они могли уехать за сотни километров от места, где были высечены.
Физический износ усложняет ситуацию.
Изучением древних надписей занимается эпиграфика. Она стоит на стыке истории, лингвистики, археологии, а иногда и криминалистики. Исследователи сравнивают надписи и ищут параллели.
Параллели помогают:
Восстанавливать текст: например, повторяющаяся формула «D(is) M(anibus) [имя] vix(it) ann(os)…» может быть подсказкой для фрагмента.
Датировать: выражения и обороты менялись от века к веку.
Локализовать: некоторые термины и сокращения встречаются только в конкретных провинциях.
Долгие годы такой поиск вёлся вручную с использованием каталогов, лингвистических корпусов и баз данных вроде EDH или EDCS. Программы в основном помогали находить одинаковые буквы, но не понимали смысла. Например, по запросу PATER выдавались тысячи совпадений, где было неясно, «отец» это или часть имени. Появление инструмента, который учитывает не только буквы, но и контекст, стало настоящим прорывом для эпиграфики.
Как устроена модель
Мифологический Эней после падения Трои собирал кусочки судьбы. Модель Aeneas собирает обломки текстов.

{kind=link}
Aeneas умеет восстанавливать утраченные куски текста, даже если неизвестно, сколько букв пропало, определять время и место создания надписи и подбирать параллели.
Для начала модель кормили испорченными текстами: из надписи убирали до 75% символов, причём пропуски делали не только точечными, но и сплошными кусками, как на настоящих артефактах. Если было известно, сколько символов пропало, то Aeneas просто заполнял пробелы. Если нет — подключался дополнительный блок, который сначала угадывал длину пропавшего фрагмента, а потом уже сам текст.
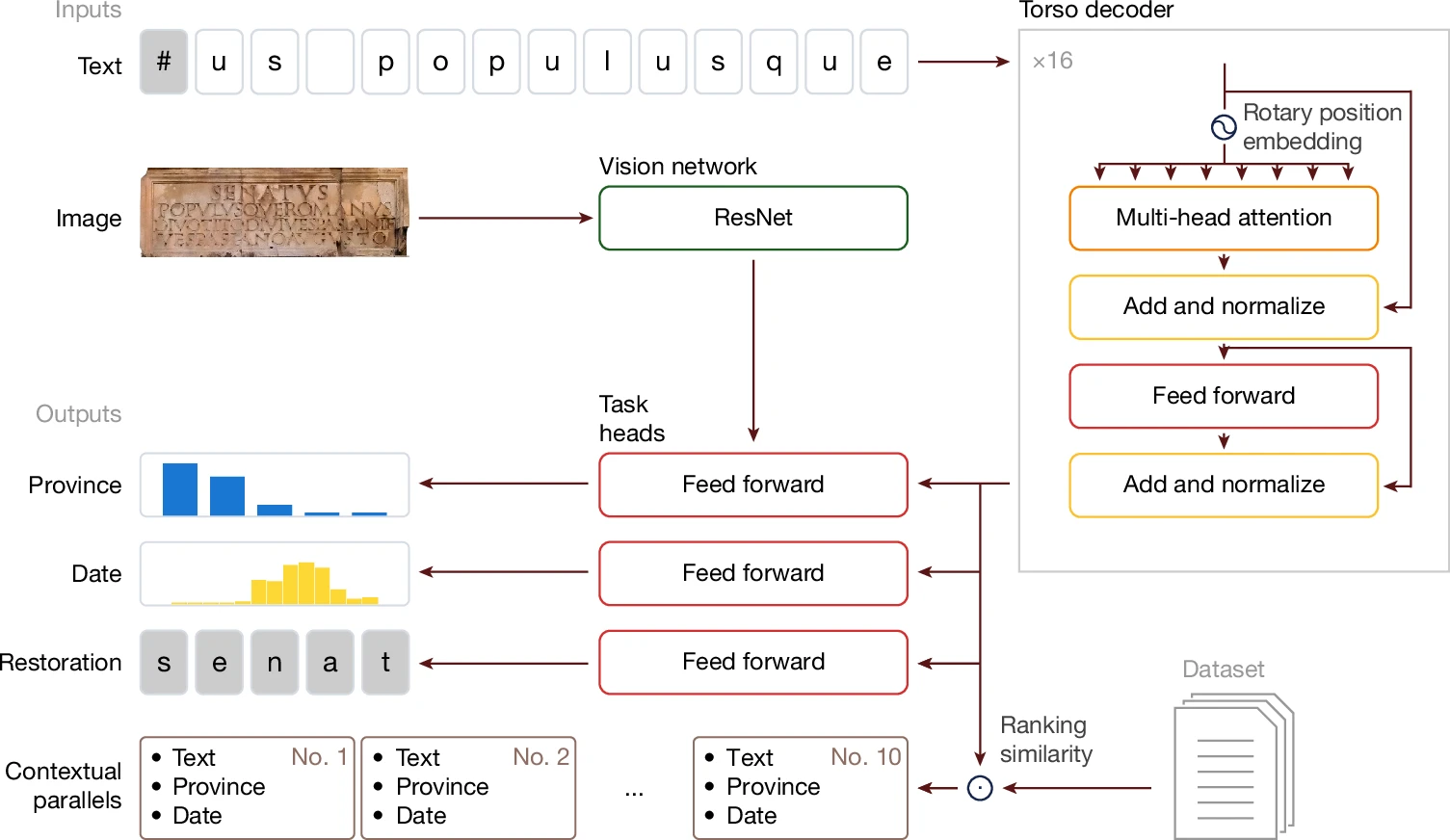
В основе модели — модифицированный T5-декодер, заточенный под три задачи: восстановление текста, датировку и определение географии. Надпись подаётся в декодер посимвольно, что позволяет учитывать орфографические вариации, нестандартные формы и обломки слов. Вместо стандартных позиционных кодировок используются RoPE (rotary positional embeddings), фиксирующие не только абсолютное, но и относительное положение символов: это особенно важно, когда текст весь в лакунах и разрывах.
После обработки декодер выдаёт промежуточные эмбеддинги, которые собираются в единое «исторически насыщенное» представление надписи. В этом пространстве поиск идёт не по буквам, а по другим признакам: поведению текста, временной рамке, ритуальной функции. Сходство оценивается через cosine similarity, что позволяет находить связи между надписями, разделёнными веками и километрами, но относящимися к одному культурному контексту.
Хотя текст остаётся главным сигналом, внешний вид камня тоже говорит о многом. Для анализа фото используется лёгкая ResNet-8, которая не читает буквы, а извлекает общие признаки: стиль резьбы, пропорции строк, материал. Эти данные учитываются только при географической атрибуции и не вмешиваются в восстановление текста или датировку, чтобы не было «подглядывания». Aeneas не делает OCR: она работает с готовой транскрипцией и не путает орфографию с дефектами поверхности.
На вход подаются транскрипция и если есть — фото плиты. Лакуны помечаются специальными символами: «-» — для пропусков известной длины, а «#» — для случаев, где модель сама решает, сколько букв вставить. Восстановление выполняется через лучевой поиск шириной 100: модель идёт от наиболее вероятного варианта и по шагам восстанавливает символы, а если встречает подозрительную лакуну, то пробует сразу несколько вариантов длины.
Дальше включаются три модуля: restoration восстанавливает текст, date определяет временной диапазон, province привязывает надпись к конкретной провинции. Поиск параллелей строится в векторном пространстве, куда спроецированы все 170 тысяч надписей: новая надпись получает свой вектор, и модель ищет ближайшие аналоги. Так Aeneas находит тексты, которые формально выглядят по-разному, но выполняют одну и ту же функцию, а также вытаскивает редкие, но релевантные примеры, которые человек легко мог бы пропустить.

{kind=link}
Для датировки время от 800 года до н. э. до 800 года н. э. разбивается на 160 десятилетий; прогноз сравнивается с экспертным распределением через дивергенцию Кульбака—Лейблера. География определяется как одна из 62 провинций с помощью категориальной кросс-энтропии. Векторное пространство учитывает всё сразу: лексику, формулы, орфографию, титулы, стилистические маркеры. Контекстуальный модуль связывает то, что невозможно увидеть при простом сравнении строк.
Чтобы показать, чем он руководствовался, Aeneas строит карты значимости: подсвечивает куски, которые повлияли на его решение. Метод спорный, но историки считают, что даже такие «подсказки» помогают понять, на что модель опирается при выводах.
Что на практике
Модель одинаково уверенно работает и с текстами, насыщенными контекстом, и с небольшими обрывками.
Первый пример — Res Gestae Divi Augusti, автобиография Октавиана Августа, в которой он подводит итоги жизни и правления.

Текст известен в нескольких копиях, но все они повреждены. Историки обычно учитывают политический контекст, титулы, даты и упоминания культовых сооружений. Aeneas пошёл другим путём: вместо того, чтобы застревать на консульских датах, модель смотрела на орфографию, институциональные маркеры и лексику. Архаичное написание aheneis (вместо aeneis) подсказало ранний период текста, титулы вроде princeps iuventutis и упоминание Ara Pacis помогли уточнить датировку. Подобранные параллели из того же времени и административного контекста привели Aeneas к реконструкции, совпавшей с экспертными выводами. При этом набор признаков, использованных моделью, был шире и сложнее, чем у человека.
Второй пример — вотивный алтарь из Майнца, небольшой фрагмент с посвящением божеству. Большая часть слов утрачена, формулы стандартные, уникальных признаков — минимум. Тем не менее Aeneas сузил лакуны до реконструкции, которая совпала с гипотезами специалистов. Географию — верхнегерманские провинции — он определил по лексике и формату, временной диапазон тоже угадал точно. Самое интересное: модель нашла почти идентичную надпись в корпусе — ту самую, на которую часто ссылаются историки.
Получается, что в больших текстах Aeneas улавливает скрытые закономерности, а во фрагментах извлекает максимум информации из минимума данных.
Время экспериментов
Чтобы проверить, насколько хорош Aeneas, команда провела эксперимент с 23 эпиграфистами — от студентов до профессоров. Им выдали набор реальных повреждённых надписей и предложили три режима работы. В первом — полная самостоятельность: только собственные знания, каталоги и интуиция. Во втором — те же надписи, но с параллелями, найденными моделью, без подсказок по восстановлению или датировке. В третьем — полный комплект: параллели плюс предсказания Aeneas с восстановленным текстом, датой и регионом.
При работе вслепую ошибка восстановления текста (CER) доходила до 39%. С параллелями она падала до 27%, а при использовании всех возможностей модели — до 21%. Географическая атрибуция без поддержки давала точность всего 27%, с параллелями — 46%, а с подсказками Aeneas — уже 68%. Датировка показывала ту же динамику: средняя ошибка уменьшалась с 31 года до 20 с параллелями и до 14 лет при использовании предсказаний модели — почти как у самой Aeneas, работающей без человека (12,8 года).
Помимо цифр, есть и субъективный эффект: историки стали на 44% увереннее в своих гипотезах, и эта уверенность коррелировала с ростом точности. Модель не подменяет человека, а усиливает его: в режиме подсказок расширяет поле зрения, а в режиме ассистента формирует рабочие версии, которые эксперт проверяет и дорабатывает. В результате тандем «человек + Aeneas» работает быстрее, точнее и спокойнее, чем одиночный исследователь.
Эпиграфика 2.0
Разумеется, Aeneas — это не генератор готовых ответов, а инструмент для выдвижения гипотез, в том числе таких, к которым исследователь шёл бы месяцами или не пришёл бы вовсе.
Из плюсов: модель работает с разными типами источников — камнями, папирусами, монетами, черепками, если там есть текст. Из минусов: она может промахнуться с датировкой или закрепить предвзятую интерпретацию. В эпиграфике, где важна каждая буква, это критично. Поэтому здесь главный принцип простой: машина ищет — человек решает.
История перестаёт быть только тем, что высечено в камне, теперь она живёт и в языковых моделях.
pavelsha
Вот важное и разумное описание области применения искусственного интеллекта. Заметьте, что это не громкие заявления о "новом подходе в исторических исследованиях" или рассказ о прелестях "AI-Vibe-эпиграфики", которые часто можно увидеть в потоке хайповых статей