
О чём эта статья
VMware не идеальная система. Исторических костылей там столько, что впору писать отдельную статью, и некоторые архитектурные решения заставляют задуматься о количестве пива на той встрече, где их принимали. Но за двадцать пять лет VMware сделала штуку, которую пока никто не повторил: собрала экосистему, в которой сложное выглядит простым. А когда сложное выглядит простым, люди забывают, насколько оно сложное, и начинают рисовать план миграции на квартал.
Broadcom купила VMware в конце 2023-го за 61 миллиард и перекроила лицензирование. Рынок зашевелился. Каждый второй вендор выпустил пресс-релиз про «замену VMware». Прошло два года. Полностью мигрировали 4%. Четыре процента. Аналитики прогнозируют, что к 2028-му уйдёт 35% рабочих нагрузок — не компаний, а нагрузок. Большинство организаций, даже уходя, будут жить с VMware на части инфраструктуры ещё годы. Эта статья про то, почему четыре.
Я проектирую и эксплуатирую enterprise-платформы виртуализации и VDI, и мне есть что сказать про то, как оно устроено на самом деле.
1. Компания, которая придумала рынок
В 1998 году группа из Стэнфорда и UC Berkeley — Diane Greene, Mendel Rosenblum, Scott Devine, Ellen Wang и Edouard Bugnion — основала компанию, которая в 1999-м выпустила VMware Workstation, а в 2001-м ESX Server. Первый коммерчески успешный x86-гипервизор. До этого виртуализация жила на мейнфреймах IBM, стоила как самолёт и была примерно так же доступна рядовому администратору.
Но история не про гипервизор. VMware создала язык, на котором индустрия до сих пор разговаривает. vMotion, DRS, HA, vSAN, NSX — это давно не просто названия продуктов, это стандарт мышления. Когда инженер говорит «live migration», он думает о vMotion. Когда архитектор рисует overlay network, он отталкивается от модели NSX — даже если строит на OVS. Proxmox, Nutanix, Hyper-V сравнивают с VMware, а не друг с другом, и это многое говорит о том, кто задаёт систему координат.
Я часто сравниваю VMware с Apple. iPhone сам по себе — ну телефон. Но AirPods + MacBook + iCloud превращают его во что-то, от чего тяжело уйти. vSphere сам по себе — гипервизор, каких несколько. vSphere + vCenter + NSX + vSAN + Aria — платформа, которую целиком не воспроизвёл пока никто. И пока этого не случилось, сравнивать гипервизоры — занятие бессмысленное. Сравнивать имеет смысл экосистемы.
2. Абстракция и почему без неё больно
Современный дата-центр — это сотни серверов, десятки тысяч VM, несколько уровней хранения, overlay-сети, compliance-политики, и всё это как-то должно работать вместе. VMware решает проблему через вложенные абстракции: ESXi прячет железо, vCenter — кластеры, vSAN — хранение, NSX — сеть. Инженер работает с resource pools, DRS балансирует нагрузку, HA перезапускает упавшие VM. Один человек с VCP-сертификацией может обслуживать инфраструктуру, на которую без этой автоматизации нужно трое-четверо. На тысяче VM это не маркетинг, это бюджет.
Memory overcommit добавляет экономической магии: на vSphere можно запускать VM с суммарным RAM больше физической памяти, и это работает предсказуемо — ballooning, TPS, compressed swap, reservations и shares на уровне resource pools. KVM поддерживает overcommit тоже, но управляемость на порядок ниже — скорее всего, о проблеме вы узнаете, когда OOM killer уже пришёл.
vSphere Lifecycle Manager описывает desired state кластера и сам приводит каждый хост к нему, эвакуируя VM через vMotion. Content Library синхронизирует шаблоны между vCenter'ами. На Proxmox — apt upgrade на каждой ноде, clone + cloud-init, и обвязка на Ansible. Работает, но это другая профессия, другая квалификация, другой уровень документирования. И когда что-то ломается на третьем хосте из пятидесяти, дебажить это сильно веселее, чем нажать кнопку в Lifecycle Manager.
Кейс: 800 VM, и всё пошло не по плану
Средний промышленный холдинг, около 800 VM, vSphere 7 + vSAN. Решили мигрировать на Proxmox + Ceph. Бюджет посчитали, timeline нарисовали, всё красиво. Гипервизор подняли за неделю. Ceph настроили за две. Дальше начались четыре месяца, которые никто не планировал.
DRS. Штука, о которой никто не думает, пока она работает. На vSphere он молча раскидывал VM по хостам, и инженеры даже не задумывались, что это вообще происходит. На Proxmox из коробки этого нет. Написали скрипт на Python, повесили на cron. Две недели работал нормально. Потом начал мигрировать VM с тяжёлым memory footprint на хост, у которого и так RAM под потолок. Поймали, когда прод начал свопить. Хорошо что заметили быстро, могло быть хуже.
Потом мониторинг. Aria Operations на vSphere показывала capacity forecasting, right-sizing, деградацию дисков. На Proxmox поставили Prometheus + Grafana. Метрики есть, forecasting — нет, и человеку нужно самому смотреть на графики и делать выводы, которые раньше делала за него система. Через три месяца команда пропустила момент, когда нужно было докупать диски. Ceph начал ребалансировку на почти заполненном кластере в пятницу вечером. Классика. Система работает, но когнитивная нагрузка на команду выросла примерно втрое, и расслабиться уже нельзя — автопилота больше нет.
3. Кодовая база, UI и точка интеграции
VMware владеет всем стеком — ESXi, vCenter, vSAN, NSX, Aria. Когда vSAN оптимизирует кеширование, он знает, как ESXi работает с памятью, потому что у них общий код. Когда DRS перемещает VM, он учитывает состояние vSAN и NSX одновременно через внутренние API. Попробуйте добиться такого с KVM + Ceph + Open vSwitch, где каждый проект разрабатывается независимо и релизится когда хочет. Интеграция между ними — ваша проблема навсегда.
vSphere Client прошёл путь от толстого C#-клиента через Flash (не будем, кто помнит тот период, тот до сих пор вздрагивает) до HTML5. Сейчас это инструмент, в котором опытный админ в одном окне видит кластер, проваливается в VM, смотрит IOPS и запускает vMotion без переключения контекста. OpenStack Horizon в сравнении вызывает... ну, скажем, сложные чувства. Proxmox честный и рабочий, но проще. Nutanix Prism ближе всех по ощущениям.
Но UI — это верхушка. Под ним — vCenter API, стабильное и обратно совместимое, обросшее тысячами интеграций за пятнадцать лет. Бэкапы, мониторинг, ITSM — всё разговаривает с vCenter. PowerCLI, Aria Automation, Enhanced Linked Mode, HCX — над API вырос целый слой автоматизации, и когда уходите с VMware, вы теряете именно его. Компания с пятьюстами Terraform-модулями и PowerCLI в каждом runbook будет переписывать это месяцами. И всегда дольше, чем запланировала, это какой-то закон природы.

4. NSX и Guest Introspection
NSX — вещь, которая заставляет сетевых инженеров либо восхищаться, либо тихо ненавидеть VMware за то, что она залезла на их территорию. Distributed firewall на уровне каждого vNIC, политики, привязанные к VM (при vMotion мигрируют вместе с машиной), load balancing, VPN, NAT — всё внутри гипервизора, без отдельных аплайнсов. Для zero-trust или PCI DSS это фундамент.
На KVM ближайшее — OVS + OVN. Чтобы собрать что-то сопоставимое, нужно склеить OVS, OVN, nftables, VXLAN/Geneve overlay и написать оркестрацию поверх всего. Проект на команду и на месяцы, причём TCO часто получается выше, чем NSX, что как бы намекает.
Рядом — Guest Introspection, и вот тут аналогов вообще нет. Антивирусное сканирование VM без агента внутри гостевой ОС: API гипервизора позволяет Trend Micro, Kaspersky, Bitdefender видеть файловые операции и память снаружи, через выделенную Security VM Appliance. Зачем: AV storm — 500 VM одновременно запускают сканирование, и кластер ложится. В VDI со linked-clone ставить агент в каждый клон — ад по ресурсам и управлению. Интроспекция работает ниже гостевой ОС, малварь не может её отключить, потому что не знает о её существовании.
Правда, интроспекция работает на уровне файловой системы — fileless malware и memory-resident угрозы она не видит. Для поведенческого анализа агент всё равно нужен, но как минимум AV storm и централизованное сигнатурное сканирование Guest Introspection закрывает.На KVM и Proxmox ничего этого нет, возвращаемся к агентам со всеми их проблемами.
5. Мышечная память
Миллионы инженеров учились работать с инфраструктурой через VMware. VCP-DCV — одна из самых дорогих IT-сертификаций. По собственным данным VMware, все Fortune 100 были клиентами. Ночью падает прод — инженер не лезет в документацию, он открывает vCenter и за секунды видит, что происходит. Контенция, latency, сетевой затык — всё на одном экране. Это рефлекс, выработанный годами, и переучиваться с него больно. В момент переучивания эксплуатация проседает, а просадка — это инциденты, которые потом разбирают на постмортемах.
Нехватка компетенций и так главная проблема IT-подразделений — это видно по любому отраслевому опросу. Добавьте переход на новую платформу. Для enterprise с тысячами VM — полтора-два года, если повезёт.
6. Всё, что держит данные: бэкапы, storage, DR
Бэкапы, storage, DR — обычно это три разных раздела в трёх разных презентациях. На практике они сливаются в одну проблему: данные привязаны к VMware так глубоко, что отдирать их — отдельный проект, по сложности сопоставимый с миграцией compute.
Бэкапы
Без CBT — full scan каждый раз. Для VM с терабайтным диском: минута против часа. Без VADP — нет app-consistent бэкапов без агента. На этих двух механизмах стоит Veeam, Commvault, Rubrik — вся индустрия. На KVM dirty bitmap появился недавно, поддерживается не всеми. Veeam для Proxmox — community-плагин. Rubrik KVM-агента не имеет.
Storage-интеграции
Storage-интеграции — отдельная боль. VAAI, VASA, vVols — через них массив «понимает» VM: hardware offload тяжёлых операций, политики хранения на уровне отдельной виртуалки, аппаратные снапшоты. VAAI, VASA — через них массив «понимает» VM: hardware offload тяжёлых операций, политики хранения на уровне отдельной виртуалки. vVols, которые должны были стать следующим шагом, Broadcom официально закопала — ещё один кусок экосистемы, который хоронит сам вендор. Dell, NetApp, HPE, Pure Storage годами оптимизировали firmware под эти интерфейсы. При переходе на KVM всё это исчезает. NetApp за полмиллиона превращается в дорогой NFS-сервер.
DR
SRM автоматизирует failover и failback между площадками, оркестрирует порядок запуска VM с учётом зависимостей. Для многих enterprise DR-план — документ, подписанный CEO. При миграции SRM перестаёт работать, и всё нужно пересобирать на других инструментах. С учётом того, что ransomware стал нормой жизни, DR — не формальность, а работающий механизм, который страшно трогать.
Кейс: ритейлер, 2000 VM и бэкапы
Крупный ритейлер, около 2000 VM. Вычислительную часть перевели на KVM-стек относительно гладко. Дошли до бэкапов — и проект встал. Veeam через VADP делал application-consistent снапшоты SQL-кластера за 8 минут. На KVM — только crash-consistent через QEMU Guest Agent. Для продуктивной базы это не вариант: compliance требует application-consistent бэкапы, аудитор не подпишет.
Три варианта: агенты внутрь каждой VM (ресурсы, управление, привет AV storm), кастомные скрипты quiescing (а потом кто их будет поддерживать?), или нишевый бэкап-продукт с поддержкой dirty bitmap на KVM. Выбрали третье. Интеграция — три месяца. Бюджет распух вдвое относительно первоначального плана. И DR пришлось пересобирать с нуля, потому что старый план целиком жил на SRM, который с новой платформой, очевидно, не работает.

7. Compliance, ISV и специализированные ворклоады
В регулируемых отраслях виртуализация вросла в compliance. Аудиторские логи vCenter — PCI DSS, HIPAA, ISO 27001. RBAC привязан к ролевым моделям, утверждённым безопасниками. Смена платформы — это пересертификация: 3–6 месяцев юристов, безопасников и внешних аудиторов. Эту строку бюджета инфраструктурная команда обычно обнаруживает уже после того, как проект утверждён. Сюрприз.
ISV-поддержка — ловушка, о которой вспоминают в три часа ночи. SAP HANA на vSphere упала — открываете тикет, вам помогают. Та же HANA на Proxmox — SAP скажет «воспроизведите на поддерживаемой платформе». Oracle известна тем, что пересматривает лицензирование при любом изменении инфраструктуры; смена гипервизора — праздник для их аудиторов. CFO понимает эту арифметику без технических объяснений: сэкономили на VMware, потеряли поддержку на ПО стоимостью в миллионы.
Отдельно — специализированные ворклоады. Horizon (Omnissa) + NVIDIA vGPU — обкатанный стек для графических рабочих мест, сертификации NVIDIA для Proxmox не существует, и без неё вы в серой зоне: NVIDIA кивает на Proxmox, Proxmox на NVIDIA. до недавнего времени сертификации NVIDIA для Proxmox не существовало — сейчас vGPU на Proxmox официально поддерживается, но экосистема интеграций всё ещё моложе, чем на vSphere
Старые гостевые ОС (2003, 2008, иногда NT) на VMware работают стабильно; на KVM virtio-драйверов для NT не существует в природе. Одно промышленное предприятие до сих пор держит NT 4.0 на ESXi — управляющий софт для оборудования за десятки миллионов работает только на NT, и никакая экономия на лицензиях не стоит риска тронуть это.
8. Бизнес-боль
Миграция среднего предприятия — минимум два года. Лицензии, железо, обучение, интеграторы. Всё это время вы платите за обе платформы: бюджет раздувается в полтора-два раза, и об этом обычно узнают после того, как проект уже продали руководству. VMDK в qcow2 конвертируется часами на терабайтных дисках, цепочки снапшотов, thick/thin, RDM — каждый случай со своими нюансами. На одном проекте конвертация с валидацией заняла четыре месяца. Четыре. Только конвертация, без самой миграции.
Каскад на сервис-провайдерах: Broadcom в 2025-м порезала VCSP-партнёров с 4500+ до нескольких сотен, к середине года осталось 13 верхнего уровня. Провайдер теряет статус — его клиенты теряют поддержку — мигрируют или уходят в публичное облако. Для провайдера с тысячей клиентов это даже не проект, это изменение бизнес-модели. А час простоя бизнес-критичного сервиса может стоить дороже годовой подписки VMware — этот факт почему-то не попадает в презентации про экономию.
9. «Никого не увольняют за выбор VMware»
CIO, который остаётся на VMware, рискует бюджетом — CFO задаёт вопросы про подорожавшую подписку. CIO, который мигрирует, рискует карьерой — простой критичного сервиса, провал DR-теста, рост MTTR. Асимметрия очевидна: за переплату никого ещё не увольняли, за упавший прод — сколько угодно.
Те, кто решаются, делают это осторожно: некритичные ворклоады, пилот, год наращивания экспертизы, и только потом основной прод. На последних конференциях в курилке слышу одно и то же — «понимаем, что надо уходить, но первым никто не хочет». Рынку нужны success stories, а их пока можно по пальцам перебрать.
10. Альтернативы
Nutanix AHV — ближайший аналог по полноте. Prism приятный, AOS закрывает compute и storage. Но вы меняете одну зависимость от вендора на другую, с поправкой на то что Nutanix ещё и привязывает к своему железу. Но вы меняете одну зависимость от вендора на другую — привязка не к железу (Nutanix давно продаёт софт через OEM: Dell, HPE, Lenovo), а к платформе AOS/Prism.
Proxmox — отличный open source продукт, KVM + Ceph + веб-UI, версия 9.0 заметно повзрослела. Для средних инсталляций — вполне. Для 5000+ VM с SLA 99.99% — пока рано, и ребята из Proxmox, думаю, сами это понимают.
Hyper-V логичен, если у вас всё на Microsoft. Linux-гости слабее, сеть уступает, но бесплатен в Windows Server — что для многих решающий аргумент.
OpenStack. Собирал дважды. Первый раз хотелось плакать. Второй раз тоже, но уже от понимания, зачем всё это нужно. Максимальная гибкость, ноль lock-in, но и сложность соответствующая. CERN и Walmart могут себе позволить команду на его сопровождение. Средний бизнес — вряд ли.
Поучительная история — Red Hat Virtualization на oVirt. Долго считалась серьёзной enterprise-альтернативой, и вполне заслуженно. Разработка остановилась примерно в 2020-м, в 2021–2022 Red Hat объявила EOL (август 2026) и переключилась на OpenShift Virtualization. Даже Red Hat с её ресурсами и KVM-экспертизой не одолела VMware на её поле и ушла в контейнеры.
Даже Red Hat с её ресурсами и KVM-экспертизой не одолела VMware на её поле и ушла в K8s-парадигму — OpenShift Virtualization запускает VM через KubeVirt, но заказчику всё равно нужен K8s-кластер, а это другой мир. Kubernetes хорош для cloud-native, но legacy не контейнеризируется по щелчку, и люди, которые пытаются запихнуть Oracle DB в pod, знают это лучше всех.
|
Критерий |
Nutanix |
Proxmox |
Hyper-V |
OpenStack |
|---|---|---|---|---|
Полнота стека |
Высокая |
Средняя |
Средняя |
Высокая* |
Vendor lock-in |
Высокий |
Низкий |
Высокий |
Нет |
Сложность эксплуатации |
Низкая |
Средняя |
Средняя |
Высокая |
Enterprise backup (CBT) |
Да |
Догоняет |
Да |
Ограниченно |
Зрелость DR |
Средняя |
Базовая |
Средняя |
Руками |
Storage-интеграции (VAAI) |
|
Ceph/NFS |
S2D/SMB |
Cinder |
Сетевая виртуализация |
Flow (микросегм.) |
Bridge/VLAN |
SDN (базовый) |
Neutron |
Agentless AV |
Нет |
Нет |
Нет |
Нет |
ISV-сертификация |
Растёт |
Минимальная |
Высокая |
Средняя |
Compliance-готовность |
Высокая |
Средняя |
Высокая |
Средняя |
Стоимость входа |
Высокая |
Низкая |
Средняя |
Низкая* |
* OpenStack: полнота высокая, но требует сборки. Стоимость входа низкая по лицензиям, высокая по компетенциям. Оценки мои, на основе опыта внедрений, конкретные показатели зависят от версии и сценария.
11. Импортозамещение в России
Всё, о чём я писал выше, компании в мире переживают как вопрос выбора. Россия переживает это как необходимость. И именно поэтому российский опыт — самый честный тест тезиса этой статьи.
Контекст
В 2018 году VMware занимала почти 79% российского рынка виртуализации. После марта 2022-го компания покинула рынок: отключила аккаунты, прекратила поддержку, закрыла базу знаний и обновления. Red Hat ушла тогда же. Microsoft ограничила продажи. Nutanix приостановила поставки. Вся «большая тройка» исчезла одновременно.
Регуляторы усилили давление. Указ Президента №166 от 2022 года установил курс на отказ от иностранного ПО на значимых объектах КИИ — с 1 января 2025 года как контрольной точкой. На практике формулировки сложнее: переходные положения, отраслевые особенности, процедуры согласования. Но вектор однозначен — ФСТЭК последовательно ужесточает требования. Для компаний на VMware в регулируемых сегментах — нарастающий регуляторный риск.
Три года спустя
Рынок отреагировал взрывным ростом. Если в феврале 2024-го в реестре было чуть больше 20 систем виртуализации, к 2025-му — под сотню. Рост почти на 98% в 2023-м, 40%+ ежегодно. По оценкам iKS-Consulting, доля отечественных решений к весне 2025-го достигла 60%, VMware снизилась до примерно 39%.
На поверхности — успех. Если копнуть — сложнее. Большинство российских платформ построены на KVM/QEMU с разной степенью кастомизации. Некоторые пошли заметно дальше, чем «KVM с логотипом».
zVirt от Orion soft — достаточно зрелая из российских платформ, и не случайно: выросла из oVirt, то есть из наработок Red Hat. В реестре с 2018 года, то есть начали задолго до того, как стало модно. SDN с микросегментацией, Terraform-провайдер, конвертер с VMware — набор серьёзный.
vStack от ITGLOBAL.COM интересен тем, что пошёл совсем другой дорогой — не KVM/Linux, а FreeBSD/ZFS/bhyve, полностью проприетарный стек без GPL. ZFS как основа хранения — дедупликация, компрессия, самовосстановление без отдельного Ceph. Разработка на C/C++/Rust, CPU overhead 2–5%. Заточена под провайдеров, и там это работает.
SpaceVM от ДАКОМ М строят полный стек с нуля: свои VDI-технологии, свой SDN-контроллер, поддержка vGPU и Эльбруса. До 96 хостов и 8000 VM — не игрушечные масштабы.
ROSA Virtualization делает ставку на безопасность: ФСТЭК, ГОСТ, в 4.0 появился DR.
Каждая из этих платформ решает задачу виртуализации. Каждая нашла свою нишу. Но все они, так или иначе, строят что-то своё. Другой UI, другие паттерны управления, другую логику. Инженеру, который двадцать лет работал с vSphere, нужно переучиваться. А переучивание — это время, ошибки и деградация качества эксплуатации.
На этом фоне отдельного внимания заслуживает Иридиум (РТ-Иридиум), потому что они выбрали принципиально другую стратегию. Не «мы сделаем по-своему, а вы привыкнете», а «мы дадим то, к чему вы привыкли, и добавим своё потом». Уже сейчас они воспроизводят значимую часть функционала VMware, и что важно — почти всё реализовано на собственном стеке. По сути, от внешних компонентов остались Linux и QEMU (и тот — форк с постоянной синхронизацией upstream). Всё остальное пилят сами: собственный гипервизор первого типа, переработанный сетевой стек, кластерная файловая система с нуля по модели VMFS, management plane, оркестрация. Специализированная сборка Linux — нельзя ничего лишнего установить или запустить, проверка подписей всех файлов, hardening на уровне базовой ОС. По UI и пользовательскому опыту — целенаправленное воспроизведение VMware: те же паттерны, та же логика, тот же «мышечный» опыт. Инженер с VCP-рефлексами садится и работает.
Важно, что это не PoC и не демо-стенд. Иридиум уже работает в продакшне — в транспортных отраслях у крупнейших игроков, в правительственных структурах, в оборонном секторе. Конкретные имена по понятным причинам не называю, но масштаб эксплуатации серьёзный. Это не теоретическая альтернатива — это платформа, которую уже чинят по ночам. И функционал наращивается быстро.
Справедливости ради: у Иридиума пока нет публичной триал-версии, и рынок это замечает — местами уже проскакивает критика про затянувшееся ожидание. По моей информации, в марте обещают выпустить версию, которую можно будет скачать и поставить самостоятельно. Пока что ребята приглашают в офис для демонстрации или, как заверяют, готовы провести полноценный пилот на мощностях заказчика: развернуть, показать, обучить и дать поработать продолжительное время. Не идеальная модель для массового рынка, но для enterprise с серьёзными требованиями — нормальный подход. Главное, чтобы публичная версия не задержалась дольше обещанного.
Disclosure: с Иридиумом знаком лично, отсюда и детализация.
Здесь стоит оспорить распространённое мнение, что «делать кальку VMware не нужно». Я с ним не согласен. На рынке enterprise-виртуализации революции не работают. Этот рынок предельно консервативен: тысячи инженеров с двадцатилетними рефлексами, процессы, вросшие в compliance, DR-планы, подписанные CEO. Когда вы приходите к заказчику и говорите «мы сделали лучше, но по-другому» — заказчик видит не «лучше», а «по-другому». А «по-другому» — это переобучение, переписывание автоматизации, перестройка процессов. То есть деньги и риски. Правильная стратегия — сначала дать как минимум тот же уровень, что был. Тот же опыт, те же паттерны, тот же порог входа. А уже потом — добавлять своё сверху. Не трёхколёсный велосипед с гениальной подвеской, а нормальный двухколёсный, на который можно сесть и поехать. Улучшать — потом.
А немалая часть из оставшейся сотни продуктов в реестре — по-прежнему KVM с логотипом. Если бы у меня был рубль за каждый «В-Название, виртуализация от настоящих профессионалов» — хватило бы на лицензию VMware.
Отдельная история — кластерные файловые системы. VMFS у VMware решает конкретную задачу: shared storage для кластера с одновременным доступом нескольких хостов. Некоторые российские вендоры закрывают это требование связкой GlusterFS + ZFS — формально кластерная ФС есть, галочка стоит, в презентации выглядит прилично. На практике — слоёный пирог, в котором каждый уровень добавляет свои задержки. ZFS сама по себе не лёгкая, GlusterFS поверх неё добавляет сетевую репликацию и метаданные, итого — деградация производительности, которую не спрячешь ни за каким бенчмарком в лабораторных условиях. На реальной нагрузке с сотнями VM это чувствуется сразу, и чем больше масштаб, тем больнее. Формально — аналог VMFS. Фактически — костыль из двух технологий, которые не проектировались работать вместе.
Чему учит российский опыт
Гипервизор заменить можно — KVM работает. Экосистему заменить нельзя — её строят заново. Аналог NSX? Развивается. Agentless AV через интроспекцию? Нет. CBT? В процессе. VAAI/VASA? Нет. Каждый элемент из разделов 4–7 — брешь, которую закрывают, но не закрыли. Отдельная проблема — зависимость от upstream: весной 2022-го GitHub и некоторые open source сообщества показали, что могут ограничивать доступ. Патч, критичный для нашей платформы, завис в upstream-ревью на три месяца. Когда не контролируешь upstream — не контролируешь roadmap.
Миграция с VMware возможна. Она происходит в масштабах страны. Но за три года VMware всё ещё на 39%. Российские компании прошли путь, который мировой рынок только начинает. Да, реально. Нет, не быстро.

12. Так стоит ли уходить?
Broadcom повысила цены, сократила партнёров, отменила бессрочные лицензии, свернула 168 бандлов в четыре, ввела минимум 72 ядра. У кого-то рост 25–50%, у кого-то — в 4–7 раз. При этом Broadcom точно знает, что делает: цена выставлена чуть ниже стоимости переключения. Для компании с десятилетней историей процессов остаться может быть рациональнее, чем уйти. Неприятно, но рационально.
Здоровый подход — сегментировать. Легаси на VMware, новые проекты на альтернативах. Гибрид сложнее в управлении, зато снижает зависимость. Аналитики прогнозируют снижение доли VMware до 40% к 2029-му. Но даже в этом сценарии она остаётся крупнейшим игроком.
Если вы дочитали до сюда, перечислять всё заново нет смысла — вы и так понимаете масштаб. Каждый фактор по отдельности преодолим. Все вместе — инерция на годы. Россия это подтверждает в масштабах страны.
VMware тяжело заменить не потому, что альтернативы плохие. Двадцать пять лет строилась не программа для запуска виртуальных машин. Строилась операционная модель индустрии — язык инженеров, экосистема из тысяч продуктов, абстракция, позволяющая одному человеку управлять инфраструктурой, для которой раньше нужна была команда. И психология, при которой остаться безопаснее, чем уйти.
Red Hat не одолела и ушла в контейнеры. Россия за три года сдвинула долю с 79% до 39%, но процесс далёк от завершения. Миграция с VMware — не замена гипервизора, а трансформация. Те, кто подходит к ней как к проекту на полгода, получают проект на два. Те, кто готов — справляются.
А что делать? Как ни странно — покупать. Не VMware. Других.
VMware выросла не в лаборатории. Она выросла в рынке — на реальных задачах, на реальных деньгах, на обратной связи от тысяч заказчиков, которые ломали ей продукт в проде и требовали починить к утру. Двадцать пять лет органического развития — вот что стоит за той экосистемой, которую так тяжело заменить. У альтернативных вендоров этого опыта нет. Но он может появиться — если рынок им поможет.
Выбрать тех, кто строит по-настоящему — не переклеивает логотип на KVM, а пишет свой стек, нанимает инженеров, решает тяжёлые задачи. Провести пилот. Купить опытный образец. Где-то, если функционала хватает, поставить в прод на некритичный сегмент. Дать разработчикам столкнуться с реальностью — с вашей реальностью, с вашими масштабами, с вашими три-часа-ночи. Потому что именно так растут продукты: не в вакууме, а в бою.
Если рынок будет сидеть и ждать, пока кто-то сделает «такой же VMware, только дешевле» — не дождётся. VMware стала VMware потому, что тысячи компаний покупали, внедряли, ломали, жаловались и покупали снова. Технологический суверенитет — это не когда продукт появляется в реестре. Это когда он прошёл через достаточно продов, чтобы стать надёжным. И это зависит не только от разработчиков. Это зависит от вас — тех, кто читает эту статью и принимает решения о закупках.
А VMware при всех действиях Broadcom остаётся платформой, которую ненавидят за стоимость и уважают за то, что она работает. Самый точный комплимент, который можно сделать корпоративному софту. Правда, на конференции я бы такое не сказал — потом полгода будут спрашивать, сколько VMware мне заплатила.
Комментарии (58)

RoasterToaster
26.02.2026 20:03Сегодня первый раз поставил proxmox. Завелась, работает. Прикольная игрушка.

x4team_only
26.02.2026 20:03Там еще есть интересная штука как PBS и бэкапы виртуалок в S3 , а еще менеджер администрирования нескольких нод (не помню точного названия, вроде в бете было еще)
RoasterToaster
26.02.2026 20:03Vsphere как то сдох, в итоге я его даже не стал переустанавливать ради пяти esxi. И так было норм, а то он как не в себя ресурсов хочет. Но аналог для proxmox я бы протестировал конечно.

werter_l
26.02.2026 20:03> не помню точного названия, вроде в бете было еще
Proxmox Datacenter Manager
Неск-ко месяцев как в релизе https://www.proxmox.com/en/downloads/proxmox-datacenter-manager
Стоит также обратить внимание на https://github.com/rcourtman/Pulse
P.s. И сюда заглянуть - может что и пригодится (нужен квн) https://forum.netgate.com/topic/163435/proxmox-ceph-zfs-pfsense-и-все-все-все-часть-2

gotch
26.02.2026 20:03oVirt попробуйте. Степень приколизма возрастёт, если вы работаете, конечно, в индустрии развлечений. И когда кластер упал - все смеются, шутят, пьют газировку и стреляют хлопушками с конфетти.

AnyKey80lvl
26.02.2026 20:03Прикольная, пока нагрузка не вырастает и api не начинает пятисотить и четырехсотить.
Траблшутинг весёлый.

Lev3250
26.02.2026 20:03Очень в тему и очень по делу. Я встречал как тех, кто пытался продать мега кластер тем, кому хватит самого простенького win server STD с двумя комплектными виртуалками, так и тех, кто красивый кластер с ha, drs и т.д. хочет перевести на proxmox причём желательно на бесплатный.

Houl
26.02.2026 20:03VMware же ещё выделялась своим компактным гипервизором который был относительно бесплатным и спокойно грузился с флэшки. Ни один из конкурентов и импортозаместителей, так понимаю, такого не может, что очень плохо.
gotch
26.02.2026 20:03Даже Microsoft попробовала и бросила. Под эту конфигурации в блейдах HP, например, были внутренние USB-порты для флэшек.
Houl
26.02.2026 20:03Да. Прям Killer Feature.

kenomimi
26.02.2026 20:03Опасная фича. У меня за 5 лет две флешки сгорели физически, прямо оплавились. Одна торчала в сервере, вторая в тридэ-принтере... Даже именитые бренды в наше время флешки делают подвальным способом из чего попало.
Времена хороших флешек на slc с нормально просчитаной электроникой давно прошли.



Malorik
26.02.2026 20:03Я тут с одну тачку (ВМ) с этого ср...гo VMWare перенести не могу а тут сотни.... Капец. Работает не трож..... Знал бы я тогда что будут такие проблемы сразу бы сел на KVM. Вообще у меня как мелкого юзера нет проблем, зачем сложности.... KVM лучшее решение для виртуализации для глупых юзеров типа меня))
gotch
26.02.2026 20:03Легаси на VMware, новые проекты на альтернативах. Гибрид сложнее в управлении, зато снижает зависимость
Всё так. Текущая инфраструктура на VMware без поддержки и патчей имеет запас прочности в 5-10 лет. Эксплуатируйте и радуйтесь, а рядом стройте велосипедик.
Мигрировать только на велосипедик без острой нужды - удовольствие ниже среднего, с новыми нагрузками проще.

MainEditor0
26.02.2026 20:03Чисто с прльзовательского опыта на домашнем ПК: раньше (N лет назад) VMWare Workstation была ощутимо шустрее VirtualBox на одном и том же железе под Windows. Но в последнее время использую именно VB, потому что... Потому

AntonVirtual
26.02.2026 20:03Ничего шустрее, чем Hyper-V вы на домашнем ПК не увидите. А его можно поставить даже в клиентской винде.
VB и WS будут примерно одинаковы и заметно медленнее. И не потому что я не люблю кого то там, а попросту потому что ВМ в гипервизоре первого типа всегда быстрее, чем второго.
Ava256
26.02.2026 20:03А как вы отличаете гипервизор первого типа, от второго. В случае Hyper-v на домашнем компе у вас хвостовая ОС где работает? А ввод вывод через что обеспечивается?



Newbilius
26.02.2026 20:03Вот как надо делать рекламу! Круто) Иридиум явно выделен на фоне всех остальных, но и почитать статью в целом было интересно и по делу.

navion
26.02.2026 20:03

NKulikov
26.02.2026 20:03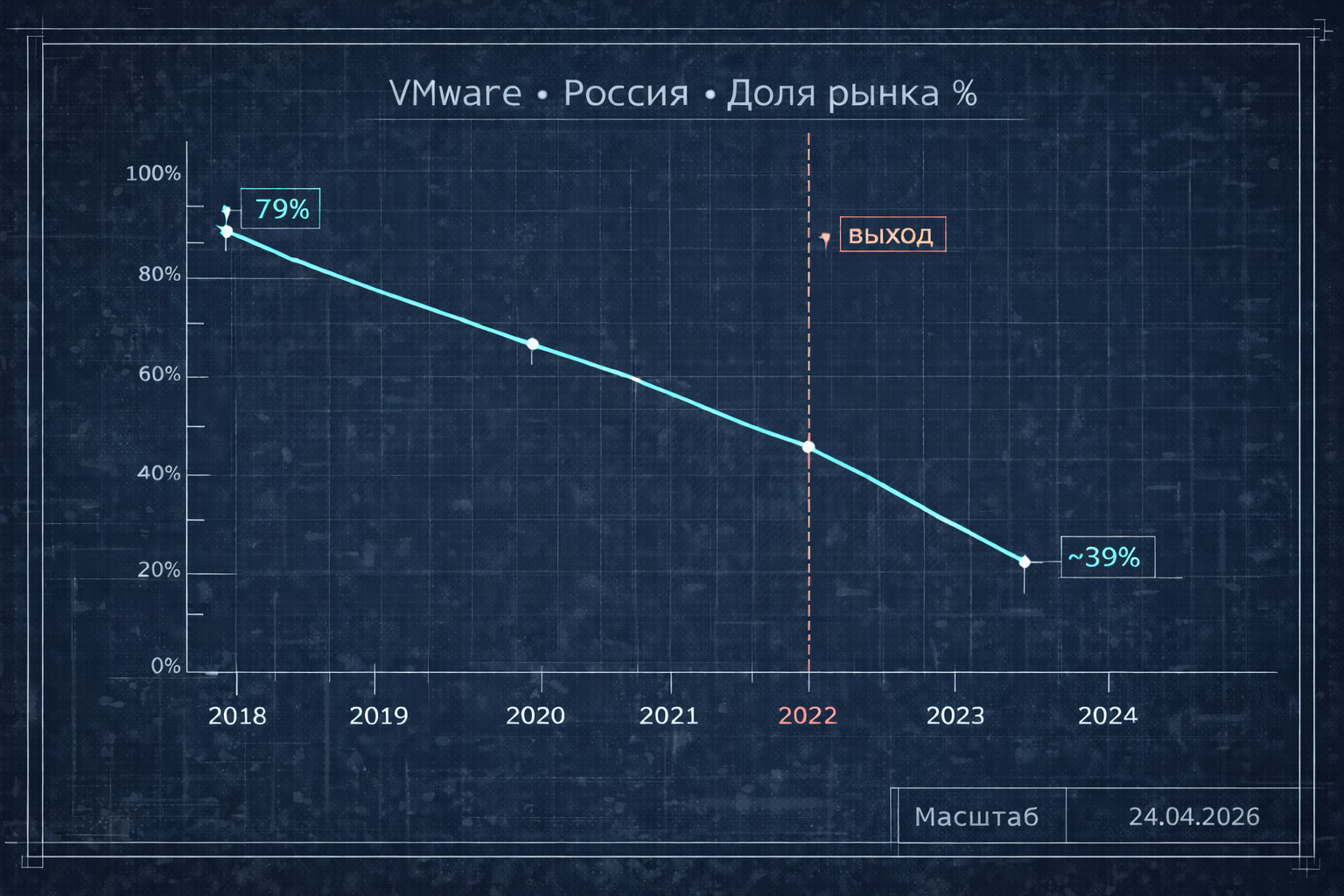
Пожалуйста, поправьте графики, которые вам LLM нарисовала руками или попросите ее нарисовать их через tools.
1.) У вас по какой-то неведомой причине, доля VMware в РФ упала с 79% в 2018 до 45% к 2022, а после 2022 до середины 2023 упала только на 6% до 39%, хотя вы пишите в тексте, что 39% "за 3 года после 2022", т.е 2025
2.) 79% на графике выше 80% и где-то в районе 90-95%
3.) 39% на графике в районе 20%.
4.) Масштаб не измеряется в дате :)
В общем, я понимаю, что LLM пыталась нагнать драматизма, но получилось это так себе. Не надо портить хорошую статью такими графиками.
NKulikov
26.02.2026 20:03Интроспекция работает ниже гостевой ОС, малварь не может её отключить, потому что не знает о её существовании.
Да, но.. Guest Introspection не видит, что происходит в RAM и процессах в ВМ. Оно может работать только, когда malware пытается записать себя на диск и тогда AV поймает сигнатуру, но давайте откровенно - сигнатурный анализ для 2026, мягко говоря, недостаточен. Куча malware file-less в принципе, другая компилирует себя на ходу на машине, третья скрывает сигнатуры. Так что агент вам нужен все равно для behavior analysis и там крайне редко используется full disk scan по расписанию в NGAV.
VAAI, VASA, vVols — через них массив «понимает» VM: hardware offload тяжёлых операций, политики хранения на уровне отдельной виртуалки, аппаратные снапшоты
vVols (а вместе с ними и аппаратные снепшоты), к сожалению, так и не получили популярность и теперь официально закопаны. https://knowledge.broadcom.com/external/article?articleId=401070 Осталось VAAI по большому счету.
Horizon (Omnissa) + NVIDIA vGPU — обкатанный стек для графических рабочих мест, сертификации NVIDIA для Proxmox не существует, и без неё вы в серой зоне: NVIDIA кивает на Proxmox, Proxmox на NVIDIA.
Существует. И vGPU на Proxmox официально поддерживается NVIDIA. https://docs.nvidia.com/vgpu/19.0/product-support-matrix/index.html И наоброт https://pve.proxmox.com/wiki/NVIDIA_vGPU_on_Proxmox_VE
Но вы меняете одну зависимость от вендора на другую, с поправкой на то что Nutanix ещё и привязывает к своему железу.
Это не так. Nutanix много лет уже продает софт, а не железо. Точнее железо от SMC они в отдельных случаях перепоставить могут, но это даже в revenue не учитывается (точнее учитывается как "Other non-subscription product revenue"). Nutanix в основном, как и VMware, продается как софт или appliance от OEM вендоров (Dell, HPE, Cisco, Lenovo, etc). Продажи железа ВМЕСТЕ с проф. сервисами меньше 5% revenue. https://www.globenewswire.com/news-release/2026/02/25/3244961/0/en/Nutanix-Reports-Second-Quarter-Fiscal-2026-Financial-Results.html
Storage-интеграции (VAAI)
Своя SDS
По мимо свой SDS, Nutanix поддерживает и внешние стораджа от Dell PowerStore/PowerFlex и Pure.
Даже Red Hat с её ресурсами и KVM-экспертизой не одолела VMware на её поле и ушла в контейнеры. Kubernetes хорош для cloud-native, но legacy не контейнеризируется по щелчку, и люди, которые пытаются запихнуть Oracle DB в pod, знают это лучше всех.
Ну.. Kubevirt, в который пошла RedHat с OS Virtualization - это все же не контейнеры. А виртуализация на QEMU/KVM, гдe Control Plane от K8s. Но с точки зрения полезной нагрузки - она живет вполне себе в нормальной/обычной ВМ.
По UI и пользовательскому опыту — целенаправленное воспроизведение VMware: те же паттерны, та же логика, тот же «мышечный» опыт.
В смысле "взяли" vCenter UI as-is, не поправили даже кнопки типа VMC on AWS? Или уже поправили ко второй версии? :)
ИМХО, это еще хуже. Люди видят интерфейс VMware (для тех кто не видел - там прямо 1:1 стыренный интерфейс, а не "по мотивам" или "списывай, но не в точь-точь"), кнопки VMware, workflow VMware и ожидают, что оно будет себя всегда ровно так же вести. А оно не будет.
Более того, многие вещи в интерфейсе VMware - не образец для подражания, а результат "наследства/legacy" + колоссальной сложности/гибкости, которой нет в "альтернативных" продуктах. Кстати, Nutanix в свое время как раз показал, как надо делать UI/UX и это было его преимуществом (правда потом там все тоже стало хуже по мере развития продукта)

lapinsa42 Автор
26.02.2026 20:03Начну с честного признания: часть фактов в статье я писал из чертогов разума, не перепроверяя. В следующий раз буду тщательнее. Ну а далее разберу по пунктам.
Guest Introspection. Принимаю. Формулировка в статье создаёт впечатление, что agentless закрывает все сценарии. На практике Guest Introspection снимает AV storm и централизует сигнатурное сканирование на уровне файловой системы. Но fileless malware, memory-resident и поведенческий анализ — только агент. В 2026-м NGAV без behavior analysis — не защита. Стоило написать точнее.
vVols. Не уследил, спасибо за ссылку. Часть экосистемы хоронит сама VMware — ирония для статьи про то, как тяжело эту экосистему заменить. VAAI остаётся.
NVIDIA vGPU на Proxmox. В моих чертогах памяти была другая картина — проверил, в матрице 19.0 Proxmox есть. Ошибка моя.
Nutanix и железо. Каюсь, формулировка устарела. Nutanix давно продаёт софт, OEM-модель с Dell/HPE/Lenovo — основной канал. Lock-in у Nutanix другого рода — привязка к AOS/Prism как платформе, но не к железу. Про внешние storage (PowerStore, Pure) — тоже принимаю, в таблице стоило отразить.
KubeVirt. Технически вы правы — OpenShift Virtualization через KubeVirt запускает полноценные VM на QEMU/KVM, K8s только как control plane. Но для заказчика, который двадцать лет работал с vSphere, «VM внутри K8s-кластера» — всё равно принципиально другая парадигма. Red Hat ушла не в контейнеры буквально, но ушла от standalone hypervisor. Формулировка в статье упрощает, согласен.
Иридиум и UI. Ребята идут своим путём. Может что-то забыли убрать, может оставили осознанно для первых версий — не мне судить их приоритеты. Скажу что знаю: те кнопки, которые я нажимал, вели куда нужно. Но моё испытание не показатель — нужны другие нагрузки, другие масштабы, другие сценарии. Понятно, что всего enterprise-функционала пока нет и они его пилят. Ваше замечание про ожидания — сильное: если люди видят интерфейс VMware, они ждут поведение VMware, и любое расхождение бьёт больнее. Думаю, ребята из Иридиума увидят этот комментарий — обратная связь ценная.
Спасибо за качественный разбор!

pavlovdo
26.02.2026 20:03Несколько лет назад тестировали Proxmox. Отказались из-за того, что community версия не такая стабильная, как подписочная, а с закупками подписки и ТП в РФ сейчас непросто.
В итоге перевезли половину VMs - не самых критичных и нагруженных: часть на RHEL (Alma) + libvirt + pacemaker + OCFS2/GFS2, и часть - на RHEL (Alma) + libvirt + pacemaker + CephFS.
Тонкая настройка ceph и pacemaker для тюнинга нагрузки - отдельная головная боль. Veeam не подключить, бэкапы переехавших VMs теперь только полные. Вывод я сделал такой - переезжать можно, но нужно заранее решить вопрос с бэкапами VMs, и заложить много time and human ресурсов на предварительные тесты.

poige
26.02.2026 20:03На первый взгляд это апология VMware (и реклама кое-чего ещё), но секунд через десять после прочтения, и явно вопреки воле автора, явственно начинает проступать настоящий бенефициар текста… — Kubernetes.
Потому что почти все перечисленные «уникальные преимущества VMware» — это на самом деле симптомы конца VM как операционной модели, а не её триумфа.
Если это неочевидно, то вы застряли где-то в районе CentOS 7 — в лучшем случае. ;)
lapinsa42 Автор
26.02.2026 20:03В долгосрочной перспективе K8s съест значительную часть, это правда. Но это не два года и не пять. Улыбнуло, спасибо за экспертное мнение.
poige
26.02.2026 20:03Я бы сказал, что значительную часть он уже сожрал, а ещё значительная часть того, что крутится на нём, на нём и начинала крутиться — без миграций вообще.
AnyKey80lvl
26.02.2026 20:03А кубер гоняют не на VM как будто в on premise. На голом железе при хороших объемах это делают только
аристократы и дегенератыотчаянные и крутые кмк.
vvzvlad
26.02.2026 20:03Куберу не нужна половина этих фишек, что в статье описано. Сдохла нода — ну и хрен с ней, новая поднимется.
x4team_only
26.02.2026 20:03Надеюсь тут не про stateful в контейнерах? Спорный момент)

JuriM
26.02.2026 20:03Стейтфул обычно все же это какой-то кластер с оператором и кворумом, способный пережить падение одной ноды/поднять новую. И там где люди имеют головную боль с пейсмейкером, то в кубе оператор эту проблему решает без головной боли

imused
26.02.2026 20:03У вас кубернетесы на железе крутятся чтоли? Дорогое удовольствие, особенно в крупных энтерпрайзах с сотнями изолированных ИС.
Почти везде кластеры k8s ставятся на ВМ, которые в свою очередь, должны где-то исполняться.
poige
26.02.2026 20:03Блин, да при чём тут «на железе» или нет(?) \@
кластеры k8s ставятся на ВМ, которые в свою очередь, должны где-то исполняться.
— если запуск кубера требует виртуализации почему-то (у которой есть свой overhead, не надо забывать — сетевой например часто весьма заметен), то для этого не нужно ничего кроме qemu-kvm или xcp-ng — да хоть headless VirtualBox, если хочется, хоть на FreeBSD с bhyve — магии VMware тут не требуется вообще, достаточно просто автоматизировать deploy. Вы же не размышляете, что там где-то ниже ещё BIOS нужен, чтобы это вообще загружалось. Слой вирты становится тут ровно тем же, по значимости, BIOS'ом — он может и нужен, но никто не строит вокруг него свою операционную модель, все давно мыслят уровнями выше.
А кроме виртуализации, кстати говоря, есть вещи типа https://github.com/loft-sh/vcluster.
НО. Суть вообще не в этом. Суть в том, где находится control plane, перешли ли вы на cattle vs pets и делаете ли вы разделение данные отдельно, а их disposable-обработчики — отдельно.

SmileyK
26.02.2026 20:03а OpenNebula - кал ?
lapinsa42 Автор
26.02.2026 20:03Не кал, но и не замена VMware. Легче OpenStack, неплохо для провайдеров и edge. Но если мерить линейкой из статьи — нет DRS, нет аналога NSX, storage-интеграции минимальные, DR руками, enterprise backup через сторонние костыли. Для своей ниши — нормально. Как альтернатива vSphere для enterprise с тысячами VM — пока нет. Поэтому и не попал в обзор, статья и большая.

swshoo
26.02.2026 20:03С проверенного ПО переходить прям больно. И это касается не только виртуализации. Сейчас только ленивый Вася NGFW не выпустил – у всех, как под копирку, под капотом сквид и обвязка из бесплатного ПО. И работают эти творения криво да косо. Но в рекламных буклетиках всё красиво и мощчно -).
swshoo
26.02.2026 20:03последним тестили NGFW ИКС - я про такой и не слышал до недавнего времени. Оказался на удивление адекватным -).

Shaman_RSHU
26.02.2026 20:03zVirt, SpaceVM. vStack... чего Basis.Dynamix не упомянули? Хотелось бы по нему тоже мнение.

andreynekrasov
26.02.2026 20:03У нас активно используется vmware, но как будто бы просто по привычке из каких то древних времен. Потому что виртуализация вообще не нужна, всё на линуксе и можно было бы запустить кластер k8s прямо на серверах (железо своё).

KReal
26.02.2026 20:03Зашёл, чтобы отметиться: клиентом на Flash пользовался, перестали вот буквально в прошлом году с переездом на Aria. А так у нас была аж специальная виртуалка, на которой были запрещены обновления и стоял IE 6 с флэшем - чтобы как раз таки в божественную консоль можно было заходить)

bazanovv
26.02.2026 20:03К вопросу о рынке - если не путаю, почти неизбежными его последствиями через некоторое время будут:
Консолидация и олигополизация рынка виртуализации в России. Выживут не все, и те, кто поставил не на ту компанию и систему - получат вторую порцию боли в подарок.
Большие проблемы с конкурентоспособностью импортозамещённых решений в случае, если / когда российский рынок откроется. Да, там где регулятор обязывает, они останутся без вариантов (возможно с ещё бОльшей консолидацией рынка). Но эффект масштаба говорит, что чтобы выжить в этот момент, необходимо заранее занимать и растить долю на международном рынке, а с этим сейчас сложно.
anonymous
lapinsa42 Автор
такой рынок)