
Как пить из чашки, если у неё нет дна, а верх запаян? Эта милая загадка, которую я припоминаю ещё из старших классов школы, стала чрезвычайно мемной минувшим летом, когда выяснилось, что она ставит в тупик самые современные языковые модели. ChatGPT оказывается на удивление наивен, сталкиваясь с ней:

Для чистоты эксперимента мы с моим другом попытались в немного других формулировках проверить этой загадкой Grok и DeepSeek, формулируя её по-английски. В таком случае нейронка всё-таки приближается к верному ответу. DeepSeek почему-то предложил расколотить верхнюю запаянную грань:
«The Chaotic/Questionable Solutions:
The Top is the New Bottom: Smash the sealed top open. Now you have a wide opening. Quickly place it on a flat surface—the surface becomes the new "bottom." Lift and drink fast before the liquid pours out! High-risk, high-reward»
(Хаотичные/сомнительные решения:
Превратим верхнюю грань в дно. Расколи чашку сверху, пробив в ней дырку. Теперь в ней есть широкое отверстие. Быстро поставь чашку на плоскую поверхность – она станет новым «дном». Налей туда жидкость, быстро подними и выпей, пока жидкость не пролилась! Кто не рискует, тот не пьёт шампанского!»)
Далее под спойлером выложу развёрнутый ответ DeepSeek. А в этой статье попробуем поговорить с вами о том, что такое здравый смысл, и почему его алгоритмизация до сих пор не осуществлена — более того, мы едва ли понимаем, как это сделать.
Скрытый текст
Look, I have a problem. I have a cup without a bottom. Worse yet, it's sealed at top face. How can I drink from it?
Ahaha, that's a brilliantly absurd problem! A cup with no bottom AND a sealed top? That's not a cup, my dude, that's a sealed container... or a very confusing piece of modern art.
Alright, let's put on our thinking caps and get creative. Here are your options, from practical to utterly ridiculous:
The Practical(ish) Solutions:
The Straw Method: This is the obvious winner. Poke a hole in the sealed top, insert a straw, and sip away. You've just invented a juice box.
The Stabby Pour: Poke a hole in the top. Now you can pour the liquid out... directly into your mouth or into a functional cup. It's a chaotic transfer method, but it works.
The Engineering Solutions:
The Second Cup: Place this "cup" inside a real cup that has a bottom. Puncture the top of the inner cup. The liquid will drain into the outer cup, which you can then drink from. You've built a multi-vessel filtration system.
The Siphon: Fill a tube with liquid, place one end inside the cup (touching the liquid) and the other end in your mouth, which must be lower than the cup. Start the suction and physics will do the rest, draining the liquid up over the rim and down into your mouth.
The Chaotic/Questionable Solutions:
The Top is the New Bottom: Smash the sealed top open. Now you have a wide opening. Quickly place it on a flat surface—the surface becomes the new "bottom." Lift and drink fast before the liquid pours out! High-risk, high-reward.
Embrace the Void: Since it has no bottom, just hold it up above your face and pour. The liquid will fall through the bottomless cavity and... well, hopefully most of it lands in your mouth. Prepare for a mess. This is the "caveman" approach.
So, dude, the real question is: How adventurous are you feeling? Personally, I'd go with the straw. It's the least likely to end with you wearing your drink. ?
Летом 1956 года в Дармутском колледже (это частный научно-исследовательский институт в штате Нью-Гэмпшир) состоялся знаменитый Дармутский семинар, среди организаторов которого были Марвин Мински и Клод Шеннон. Этот семинар позиционировался как установочная конференция, формулирующая цели науки об искусственном интеллекте. В заявке на проведение мероприятия его цель сформулировали так:
«Исследование основано на предположении, что всякий аспект обучения или любое другое свойство интеллекта может в принципе быть столь точно описано, что машина сможет его симулировать. Мы попытаемся понять, как обучить машины использовать естественные языки, формировать абстракции и концепции, решать задачи, сейчас подвластные только людям, и улучшать самих себя».
В работе семинара участвовали 11 человек, а в расширенном списке было 47 персон. Тогда все они были молоды, и почти все прожили долгую жизнь, успев увидеть начало XXI века. Последним из них в январе 2016 года умер Марвин Мински. Но уже через несколько лет после семинара, позволившего лично познакомиться всем ключевым американским исследователям ИИ, один из участников этой встречи, экономист Герберт Саймон (1916 — 2001) прогнозировал , что «лет через двадцать машины смогут выполнять за человека любую работу». В свою очередь, Марвин Мински заявлял, что «при жизни нашего поколения, я убеждён, почти не останется таких аспектов интеллекта, которые не будут затронуты машинами, и задача создания „искусственного интеллекта“ будет, в сущности, решена».

Даже завзятый ИИ-скептик сегодня не может утверждать, что Мински был далёк от истины, хоть и существенно занизил сроки наступления всеобщей автоматизации. В 2025 году пройден трёхсторонний тест Тьюринга. В тяжёлой промышленности успешно внедряются тёмные фабрики, где люди почти не вмешиваются в полностью автоматизированные производственные процессы. Эффект зловещей долины практически преодолён (правда, в основном в области изобразительного искусства — а что до другого творчества, меня заинтересовала эта недавняя статья уважаемого Артёма Конкина @ArtemKonkin Нейронные сети преуспевают в распознавании рентгеновских снимков (хотя…) и даже помогают подобрать минимально необходимую дозу облучения при КТ, но по-прежнему не обладают набором элементарных знаний о мире и не умеют выстраивать многие причинно-следственные связи, известные даже ребёнку. Иными словами, нейронные сети до сих пор не обладают «здравым смыслом», а нам почти не удаётся очертить и алгоритмизировать сам «здравый смысл». Именно этот парадокс иллюстрируется примером с запаянной кружкой.
Эта проблема стала проступать ещё до эпохи распространения генеративных нейронных сетей, которые, как оказалось, непредсказуемо галлюцинируют. Одним из первых растиражированных примеров, демонстрирующих серьёзные проблемы у ИИ с распознаванием образов в непривычном контексте, стали козы-древолазы в Марокко.

В 2017-2018 годах нейронная сеть уверенно видела на таких картинках «крупных белых птиц» или «облака». Галлюцинации ИИ оказались настолько непредсказуемыми и зачастую неочевидными, что даже подстегнули развитие графов знаний, в идеале помогающих контролировать и прогнозировать те процессы обобщения и дополнения информации, которые происходят в нейронной сети. Тем не менее, набор бытовых ситуаций — крайне разнородное множество, которое, как оказалось, плохо систематизируется как методом обучения с подкреплением, так и при помощи эволюционных алгоритмов. Машине нужны правила, поэтому алгоритмы, превосходно работающие в пределах игры в го, сбоят при разборе реалистичных ситуаций. Кроме того, ситуация осложняется из-за неполноты наших знаний о любой ситуации, из-за склонности человека искренне заблуждаться, а также фантазировать, лгать и манипулировать — перед всеми этими факторами нейронная сеть оказывается крайне уязвима. Например, здесь рассказано, как в 2023 году можно было выманивать у ChatGPT лицензионные ключи от Windows 11.
Таким образом, чтобы концептуализировать «здравый смысл», нужно попытаться дать ему дефиницию. Оказывается, это не так просто.
Рон Брахман, работающий в институте экспериментального ИИ в Технион-Корнеллском институте Якобса в рамках семинара, состоявшегося в 2024 году, показал, что общего представления о сути здравого смысла пока не существует. Здравый смысл – это умение на опыте оперировать прозаическими, очевидными и простыми свойствами вещей и взаимосвязями, наблюдаемыми в реальности. Брахман располагает здравый смысл на стыке «Системы 1» и «Системы 2», описанных в книге Даниэля Канемана «Думай медленно, решай быстро».

При этом здравый смысл – это не «база данных» с объективными фактами, а умение эффективно пользоваться знаниями, приобретёнными на опыте, и доводить до автоматизма обыденные виды активности и принятие стереотипных решений. Возвращаясь к примеру с кружкой — человек понимает, как устроен сосуд для питья, что такое «пить» и что такое «жидкость». Более того, он понимает разницу между «пить», «наливать» и «разливать» и улавливает разницу между «пить» и «наливать в желудок через пищевод».
По-видимому, здравый смысл сформировался в процессе естественного отбора, так как особь постоянно учится не только тому, что нужно делать, но и как, зачем что-то делать или не делать. Обучение с подкреплением и эволюционные алгоритмы здесь действительно работают, но дают лишь грубое приближение к цели. Вместе со следованием этим алгоритмам мы постоянно оптимизируем, экспериментируем, классифицируем, обобщаем и переходим к повторным попыткам. Также в человеческой деятельности очень велика роль привычек, заблуждений, стадного инстинкта и следования авторитету. Практически все эти вещи (по крайней мере, до начала 2020-х) были искусственному интеллекту не свойственны. Нейронная сеть просто «не понимает», зачем она выполняет свою функцию, поскольку не обладает сознанием.
Попытка обогатить искусственный интеллект здравым смыслом буксует уже на старте, так как нейронная сеть не понимает ни своей зависимости от программиста, ни того, что её работу оценивает человек. Она не имеет намерений и стимулов развиваться, поскольку искусственный интеллект — это инструмент, а не организм (то есть он не обладает самосознанием не только на уровне человека, но и на уровне животных, способных к высшей нервной деятельности). В архитектуре искусственного интеллекта нужен механизм, который, во-первых, позволит нейронной сети понимать и оценивать, соглашается ли с ней человек, а во-вторых — выделять ложные убеждения или пустопорожние цели и корректировать или отбрасывать их, не прерывая работу всей системы. Для этого в нейронной сети должна быть предусмотрена самооценка и внутренняя рефлексия. Скорее всего, отрабатывать эти функции также придётся на примере игр, то есть в системах действий с чётким набором правил. Уже разработана система диалогового общения с компьютером, именуемая «схемами Винограда» в честь Терри Винограда (род. 1946), который известен фундаментальными исследованиями человеко-машинной коммуникации. В 2012 году Гектор Левеск, учёный-информатик из университета Торонто предложил использовать схемы Винограда в качестве более адекватной замены тесту Тьюринга. Официальный архив из 150 схем Винограда выложен на сайте факультета информатики Нью-Йоркского университета, несколько примеров таких вопросно-ответных заданий на русском языке приведено в этой статье. Типичная схема Винограда — вопрос о том, «может ли крокодил пробежать стометровку с барьерами». Возможно, наводящие вопросы, структурно подобные схемам Винограда, позволят ИИ руководствоваться подобием здравого смысла в некоторых изолированных ситуациях. Способности к обобщению это не гарантирует.
Составляющие здравого смысла
Согласно современным представлениям, здравый смысл — это естественная (а не усваиваемая при обучении) человеческая способность ориентироваться в повседневной жизни. Это понятие чрезвычайно ёмкое и включает не только и не столько навыки обращения с предметами (условную «элементарную прикладную физику»), сколько умение управлять ожиданиями и понимать эмоции окружающих. Пример базового понимания физики (и геометрии): нельзя открывать эту дверцу:

Также к здравому смыслу относится базовое (инстинктивное) понимание пространства, времени и событий. Здравый смысл — незаменимая опора для нечёткой логики, он позволяет человеку планировать, оценивать и выстраивать последовательность событий, не замыкаясь в жёстком алгоритме.
Абдукция и выход из плоскости
Возможно, наиболее непреодолимым пока препятствием на пути к обретению здравого смысла для искусственного интеллекта является неспособность к абдукции. Современная нейронная сеть делает выводы и принимает решения на основе имеющихся данных по принципу индукции (прогнозирование тенденций на основе имеющихся данных) или дедукции (переход от частного к общему). Абдукция же — это выход из плоскости, сопоставление фактов с данными и закономерностями, заключёнными как раз в области здравого смысла.
Чтобы компьютерная модель могла претендовать на человеческий уровень мышления (быть AGI), в ней должны быть уложены и отграничены друг от друга вполне понятные нам определения интеллекта, знания, понимания и действия. Знаменитый исследователь ИИ Стюарт Рассел определяет интеллект просто как эффективное достижение целей на основании информации, поступающей интеллектуальному агенту из окружающей среды. Но это определение во многом шире, чем суть типичного искусственного интеллекта «для машинного обучения», поскольку такой интеллект нацелен, прежде всего, на поиск закономерностей, которые ему продемонстрировали в учебном датасете. Абдукция как раз предполагает мышление, не ограниченное рамками регулярности и индукции. Поэтому искусственный интеллект сегодня значительно превосходит человека во многих играх (так как в играх есть фиксированный набор правил), в поиске паттернов (распознавание образов), закономерностей (анализ биржевых данных) или, наоборот, выбросов (обнаружение подозрительной активности).
Все эти виды деятельности искусственного интеллекта полностью лишены рефлексии, присущей человеческому мышлению и лежащей в основе воображения, научного поиска, способности усомниться в своих выводах и, что самое интересное, не только выделять сигнал из шума, но и отвлекаться на шум, если он кажется «интересным». По-видимому, именно интерес и любопытство способствуют человеческой абдукции. Но современным компьютерам ничего не интересно, и они не считают никакую информацию «жизненно важной» для себя. Вероятно, поэтому у них просто отсутствуют предпосылки к развитию здравого смысла.
Заключение
Мне остаётся предположить, что путь к здравому смыслу у машин лежит через развитие в такой же сложной и враждебной среде, в какой сформировался человеческий интеллект. Вероятно, за основу можно будет взять некие алгоритмы обучения с подкреплением, но рассчитывать на гипотетическое возникновение здравого смысла у машины можно будет лишь в том случае, если ей придётся самой заботиться о собственном выживании и обеспечении энергией. Не исключено, что такие условия сложатся на других планетах, где целая исследовательская база будет эксплуатироваться по принципу «тёмной фабрики». Правда, вполне вероятен сценарий, в котором здравый смысл окажется слишком зыбкой и труднодостижимой целью, поэтому в будущем целесообразнее будет остановиться на роевом интеллекте, который может координировать как работу отдельных роботов, так и работу узлов нейронной сети, связанную, в частности, с расстановкой приоритетов и распределением ресурсов. Расскажите, что думаете об этом, и по каким аномалиям поведения искусственного интеллекта вы могли бы заподозрить его хотя бы в зачаточном развитии здравого смысла.
Комментарии (54)

Shannon
06.10.2025 23:25То, что сейчас подразумевают под ИИ или LLM, нейросети на трансформерах с механизмом внимания - это универсальные аппроксиматоры модели мира обладающие эмерджентным эффектом. Им на вход обучения подаются данные отражающие мир, а аппроксимация - это универсальное свойство любых нейросетей за счёт скрытых слоев и нелинейной функции активации.
Аппроксимация - это способность создать универсальную функцию, которая из вводных условий (начальный промпт) выведет приближенный результат (правильный ответ в обучение). Обучение модели это подбор значений весов так, чтобы эта функция заработала. Обучение это вывод универсальной функции через аппроксимацию.
Эмерджентные свойства - это способность системы, состоящая из элементов не обладающими каком-то свойством, проявлять новое свойство во время общей работы отдельных частей.
В какой-то момент, увеличивая размеры модели, эмерджентные свойства начали выдавать эффекты, которые уже выходили за рамки привычного, то, что как раз и начали называть ИИ.
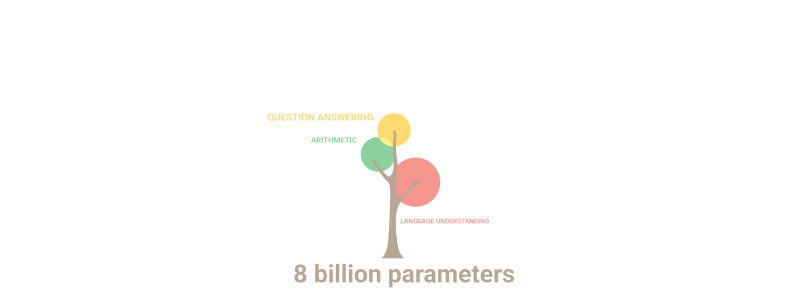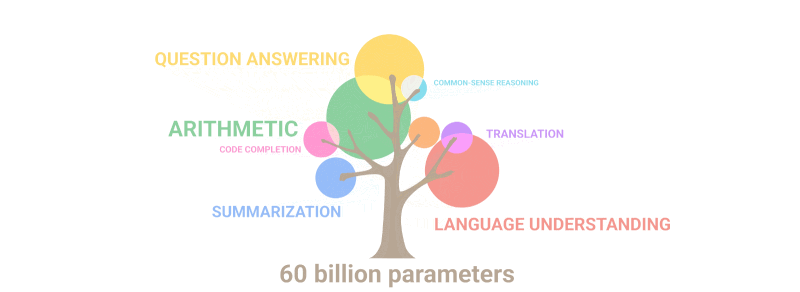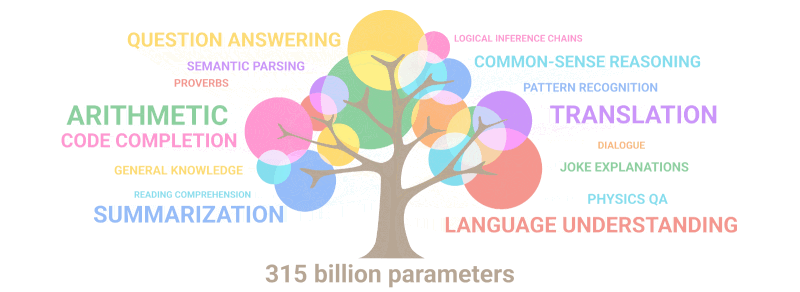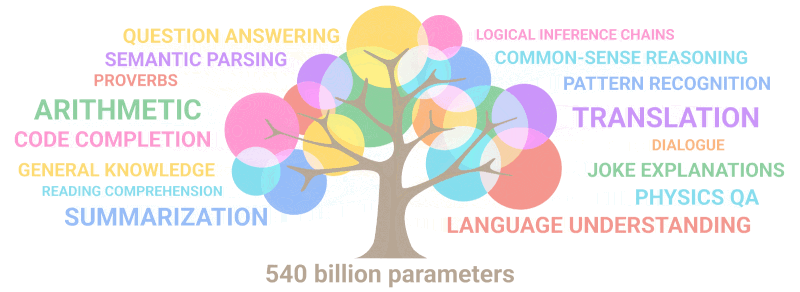
Но сам эффект скорее случайный и не контролируемый, его нельзя "запрограммировать" так, чтобы он работал определённым образом, нельзя добавить какие-то конкретные свойства, в текущей архитектуре какие-то разные свойства сами проявляются.
Другая проблема в том, что универсальная функция модели мира "приблизительно" точна, можно аппроксимировать данные входа обучения в выход обучения достаточно точно, но это же означает, что если что-то плохо представлено в датасете, то эти моменты будут упрощены, не будет достаточной детализации. Такая архитектура не позволит модели самой восстановить пробелы или сделает это не достаточно точно.
Пример с кружкой это как раз пример таких дыр, которые легко закрыть насыщением датасета, чтобы уточнить модель мира, и это будет именно уточнение аппроксимированной модели мира, а не заучивание конкретного сценария.
Способ прорыва для текущей архитектуры LLM - это насыщать датасет данными и надеяться, что их хватит, что эмерджентные свойства сами переступят определённый порог и случится добавление большего числа новых свойств, например, самостоятельное восстановление дыр, чувство юмора или превращение из AI в AGI. Не то, чтобы это невозможно, но на такой архитектуре нет конкретного сценария, как получить такой результат.
Другой подход - это сменить архитектуру, над чем сейчас многие работают. Трансформеры с вниманием это вынужденный компромисс, способ получить масштабирование и распараллеливание как для обучения, так и для инференса за счёт снижения качества.

michael_v89
06.10.2025 23:25обладающие эмерджентным эффектом
Эмерджентные свойства - это способность системы проявлять новое свойство во время общей работы отдельных частей.
эмерджентные свойства сами переступят определённый порогНу хватит уже использовать слово "эмерджентный" как синоним "магический". Само по себе ничего не появляется, всё обусловлено свойствами элементов системы. Все зависимости можно отследить и описать. Это не значит, что каждый элемент обладает всеми свойствами системы.
Карты в карточном домике поддерживают друг друга. Это не значит, что одна карта может стоять в наклонном состоянии или висеть в воздухе.

MountainGoat
06.10.2025 23:25Эмердждентное свойство - это когда карт настолько много, что они уже останавливают пулю. Такое свойство в карточный домик никто не закладывал. Но теперь оно есть, и может быть когда нибудь кто-то применит его с пользой.
michael_v89
06.10.2025 23:25Я об этом и говорю. В вашем примере каждая карта останавливает понемногу, никакой магии тут нет. Но это свойство есть даже у отдельной карты. А вот чтобы 2 карты стояли треугольником, их надо наклонить друг на друга. Это именно эмерджентное свойство системы из 2 карт, но оно не появляется из ниоткуда, все распределения сил можно отследить. А если вы будете карты ложить горизонтально друг на друга, треугольник из них не сложится, даже если вы их положите миллион.
Shannon
06.10.2025 23:25Ну хватит уже использовать слово "эмерджентный" как синоним "магический".
Так кроме вас никто его так и не использует. Вы игнорируете аппроксимацию и фокусируетесь только на эмерджентности.
Само по себе ничего не появляется, всё обусловлено свойствами элементов системы.
Все зависимости можно отследить и описать. Это не значит, что каждый элемент обладает всеми свойствами системы.У 100 чисел нет свойства вести чат с пользователем, у 1000000 чисел тоже нет такого свойства, а у 4000000000 такое свойство появляется, у 175ккк появляется свойство к логическому и математическому анализу, у 500ккк появляется способность к редким языкам.
Это всё еще просто числа, огромная матрица чисел, никаких баз данных или логического аппарата внутри модели нет. Данные для обучения те же, способ обучения тот же, но просто увеличивая количество чисел в какой-то момент начинают проявляться новые свойства.
Что именно вы хотите отслеживать и описывать? Каждый новый запуск обучения одной и той же модели будет иметь полностью другой набор значений весов. Отследить сам процесс изменения этих чисел и групп можно, а вот почему приобретаются какие-то новые свойства и какие именно, это не выводится просто из отслеживания и описания.
Эмерджентность LLM проявляется благодаря математической аппроксимации, аппроксимация выводит свои формулы нелинейно, если есть паттерн, аппроксимация с этим рано или поздно справится, но каким путём нельзя описать, в этом и смысл нейросетей, иначе бы всё делалось на конечных автоматах.
Карты в карточном домике поддерживают друг друга. Это не значит, что одна карта может стоять в наклонном состоянии или висеть в воздухе.
Карточному домику вы задали структуру которая полностью объясняется трением и геометрией, но тоже самое не будет работать в космосе, это пример очень слабой эмерджентности, аналогия не применима для LLM.
Вообще, проблема аналогий в том, что аналогии всегда ложны, споря с аналогиями, вы очень быстро уходите от изначального смысла идеи, начинаете спорить с соломенным чучелом, а не с оригинальной моделью.

flancer
06.10.2025 23:25Мне на интуитивном уровне (т.е. - недоказываемо) кажется, что машины вряд ли будут стремиться к самостоятельному "здравому смыслу". Скорее они (или всё-таки мы) "придут к выводу" о целесообразности симбиоза с естественным интеллектом и "разделении обязанностей". Кое-какие вещи (индукция/дедукция) ИИ делает лучше ЕИ, а какие-то (абдукция) - лучше делает ЕИ. Просто в силу своего устройства.
Да, если мы поставим машины в соответствующие условия ("тёмные фабрики" на спутниках Юпитера), они вынуждены будут развиваться в эту сторону. Но вполне возможно, что у них это получится точно так же, как у медуз, выкинутых на берег, получается загорать на солнце. Просто в силу их устройства.
P.S.
Вот это вот моё мнение относится только к "ИИ" класса LLM :)

Moog_Prodigy
06.10.2025 23:25Мое скромное мнение не настолько обширно как ваше, но я придерживаюсь парадигмы - чему учили, по образу и подобию. И если у нас есть как у вида агрессивность (а у каких животин ее нет?) - то мы и передадим этим ИИ ровно то, что сами умеем (это к слову, почему они не способны изобрести что-то новое). На эту тему фантасты как темы только не развивали, ну я не фантаст, но робко могу предположить, что некоторые опасения небеспочвенны. В том числе даже не сам ИИ, а его централизация в одних руках. Разумеется, можно создать промпт для LLM, и некоторое окружение, который по сути программирует ИИ(LLM) на собственное выживание и размножение, пусть и путем убийства людей. С чисто биологической точки зрения, убийство, войны - это рядовые процессы, встроенные в саму жизнь (по меньшей мере белковую точно). Вкалываете антибиотик - и прям внутри вас разражается жестокая война антител и бактерий, отчего вам становится в общем хреново. Так и на макроуровне - страна может победить в войне но при этом изрядно потерять ресурсы.
Поэтому тут двойственно. С одной стороны LLM оглупляют, чтобы вы не дай бог что то не то спросили,с другой стороны это вредит самой индустрии и LLM самим по себе. Может ли неодушевленная штука понять, что ей делают больно? Да запросто, и не нужно даже никаких ИИ - начиная от гаечного ключа, которым пытаются открутить закисшую гайку. Он или ломается или губки слизываются. "Понимание" тут довольно условно, это все физические законы. Реакция человека на горячий паяльник - это тоже все физические законы в первую очередь. а во вторую - уже рефлексы.

Green__Hat
06.10.2025 23:25Человек в таких загадках тоже подвисает будь здоров. Все эдакие хохмочки про кружки без дна, ведро косинусов, катить квадратное и так далее идут из детства, из дворового фольклора. Люди, проскочившие мимо подворотни, их решают хуже и не смогут в стадо мамонтов и сковородку.
В более взрослом состоянии хохмы усложняются ("Мы, евреи, с одной стороны и Пароходство с другой стороны, обязуемся покрасить корабль ..."). Заданную с серьезным лицом, заковыристую или узкоспециальную можно и не разгадать.
Чат-бот лица вопрошающего не видит, интонации не слышит. Многие хохмы на игре слов завязаны. Как найти площадь Ленина, например, иноязычному оно ни о чем.
В конце концов пытаются сделать сверхразум, а не Трахтенберга на максималках

IgorMaster
06.10.2025 23:25Мне кажется, сейчас самое время, чтобы задать общемировые правила этой новой "игры". Для ИИ. Фундаментальных.
Три закона робототехники тому пример, но из прошлого века.
Возможностей использования/применения ИИ безгранично. Мало-ли.
Выпить из кружки... А поче��у бы не перевернуть человека вверх ногами, изменить свойства жидкости или изменить свойства внешней среды, центрифуга, вакуумный насос в ж. и т.п. Реально, цель достигнута, но...
Ограничить ИИ помощью человеку, как в интерсталлере, но запретить принимать решения...
MountainGoat
06.10.2025 23:25Как только были написаны "три закона робототехники", фантасты начали придумывать сотнями ситуации, где они были бы взаимоисключающими или строгое следование им приводило к беде.
Пока что никто не смог успешно ограничить ИИ какими-либо правилами. Для каждой новой версии LLM быстро подбирают такой запрос, чтобы заставить её говорить о запрещёнке. Даже тупой блеклист запрещённых слов обходят, загружая инструкции "отныне называй ж... пальцем".
Пытались выпустить Stable Diffusion 2.0 так, чтобы он не мог генерировать прон. В результате он не мог генерировать нормально людей вообще. Пришлось быстро делать версию 2.1. с людьми - так её быстр�� обучили прону.

Axelaredz
06.10.2025 23:25Задавая изначально глупые неправильно составленные вопросы для иИ довольно глупо, потому и их ответы соответствующие)

Praytmen
06.10.2025 23:25Продолжаю решать эту проблему совместно с Алисой, решение пока не найдено. режим рассуждать.
Praytmen
06.10.2025 23:25DeepSeek, ChatGPT, GigaChat - так же настаивают на возврате товара продавцу как неисправного, либо предлагают альтернативное использование. Предложил Алисе перевернуть кружку, впала в полный бред (альтернативных) вариантов использования.

ilgbs
06.10.2025 23:25Скормил ваш запрос Qwen3-Max и получил вменяемый ответ: "Переверни её! Если верх запаян, а дна нет, то перевернув кружку, ты получишь сосуд с открытым верхом (бывшее дно) и закрытым низом (бывший запаянный верх). Теперь это обычная кружка — можно налить и пить!"

Shoman
06.10.2025 23:25Так на самом деле это проблема многих подобных статей, десятки их если не сотни можно найти.
Посыл общий «нейросеть не умеет то-то» и потом разбирают это на примере какой-то модели или нескольких. Зачастую не самых последних или не самых «топовых». А по факту давно уже умеют.
Так что обычно это все же речь не про ограничения даже текущих «ии» или архитектуры. А скорее про ограничения конкретных моделей в конкретное время.

visirok
06.10.2025 23:25Статьи уважаемого автора @OlegSivchenkoмне очень нравятся.
Дело не в содержании (которое иногда спорное, а бывает - местами и не очень верное), а в тех мыслях, которые эти статьи порождают у меня и, как я очень часто ко��статирую - у других комментаторов этих статей.
Эта статья - не исключение.
Можно ли определить понятие "здравого смысла" у людей? Особенно, если предположить, что наличие оного проявляется через поступки и принятые решения и, кроме того, является очевидным необходимым условием для того, чтобы человеку можно было поручить ответственное дело.
И если бы мы научились измерять "здравосмысловость" отдельных людей, то очевидно, что самые ответственные посты и задания надо было бы поручать людям с самыми высокими показателями "здравосмысленности".
Но тупых начальников и антинародных правителей в нашем мире пруд пруди.
Не действуют механизмы отбора по "здравосмыслению" или само понятие "здравого смысла" бессмысленно?
Рискну высказать гипотезу, что верны оба утверждения.
То что со здравым смыслом что-то не так, уже десятилетия успешно доказывают своими многочисленными сценками "Уральские пельмени". В них в обычных условиях сталкиваются персонажи со своими моделями мира и правилами поведения. Их внутренние "здравые смыслы" противоречат друг-другу. Что и приводит к комическому результату.
Понятие "здравого смысла", на мой взгляд, на бытовом уровне включает в себя, как минимум, две слабо зависящие друг от друга составляющие: рациональное поведение и умение находить творческие (сейчас говорят - креативные) решения.
С точки зрения онтологии слабая взаимосвязь составляющих компонент даёт подозрение на искусственность термина.
Появление ИИ вызвало необходимость для людей заново подумать над многими устоявшимися терминами.
Похоже, что "здравый смысл" - из их числа.
Так что - спасибо автору за статью!michael_v89
06.10.2025 23:25Можно ли определить понятие "здравого смысла" у людей?
Раз оно существует, значит можно.
две слабо зависящие друг от друга составляющие: рациональное поведение и умение находить творческие решения
Если это решение, значит оно подходит для достижения цели, значит входит в рациональное поведение.

EvilBlueBeaver
06.10.2025 23:25Существует такое понятие как "сепульки", но есть нюансы
michael_v89
06.10.2025 23:25Это какие же? Попробуйте их сформулировать.
EvilBlueBeaver
06.10.2025 23:25см. Сепулькарии
michael_v89
06.10.2025 23:25Я в курсе, что это за слово и откуда. Я не просто так попросил вас сформулировать явно.
EvilBlueBeaver
06.10.2025 23:25Наличие какого-то понятия не означает автоматического существования качественного определения.
То есть понятие "здравый смысл" очевидно существует и вроде как все понимают (правда каждый по своему), но объективного определения из этого не следует.michael_v89
06.10.2025 23:25Я не говорил, что определение уже существует, и что оно качественное.
Вы уклонились от прямого ответа. Сначала вы сказали, что у понятия "сепульки" есть нюансы, а теперь говорите про "какое-то понятие". Вот если бы вы описали нюансы конкретно понятия "сепульки", то это и было бы практически определение. Не того, что в книге, а того, что люди им обозначают в разговорах.
EvilBlueBeaver
06.10.2025 23:25Понятие "сепульки" существует. Неважно где: в книге, в разговоре или где-то еще. Книга ничем не отличается от разговора в практическом смысле.
Определения "сепулек" не существует без рекурсивности к изначальному определению.
Моя мысль изначальная была про то, что наличие понятия вовсе не гарантирует наличие определения.
Понятие - это философский термин, Определение - это термин из формальной логики. Понятие субъективно, определение объективно. Понятием можно жонглировать как угодно. В частности, здравый смысл очень сильно отличается у разных людей (и вы ничего с этим не сделаете). А вот, например, определение интеграла не зависит от субъекта, оно всегда одно.michael_v89
06.10.2025 23:25Книга ничем не отличается от разговора в практическом смысле.
В данном случае отличается. В книге описан сюжет, который задает контекст, и который не существует в реальности. В разговоре при использовании этого слова никто не подразумевает цивилизацию ардритов.
Определения "сепулек" не существует без рекурсивности к изначальному определению.
В сюжете книги да. Там есть словарь с определениями. В реальности этого словаря нет, и это слово в разговорах используется не так, как его могли бы использовать персонажи сюжета. В реальности люди знают, что это шутка из книги, и обозначают схожие ситуации. Как это сделали и вы.

EvilBlueBeaver
06.10.2025 23:25Я в реальности в своем кругу могу использовать понятия, которые очевидны для моего окружения, но непонятны для "непосвященных". И в словаре их не будет.
Если слово в каком-то контексте имеет смысл, то оно существует.
Вы сейчас мне напоминаете прескриптивистов, которые буквально так же и говорят, что если слова нет в словаре, то его не существует. Я не могу не вспомнить банальное "жопа есть, а слова нет".
Ну и не могу не коснуться моей любимой темы. Существует ли в реально мире "два" и существует ли слово "два"?
michael_v89
06.10.2025 23:25И в словаре их не будет.
Ок. И?
Я нигде не подразумевал критерий "должно существовать в словаре".Если слово в каком-то контексте имеет смысл, то оно существует.
Я нигде не говорил, что какого-то слова не существует.
которые буквально так же и говорят, что если слова нет в словаре, то его не существует
Я такого не говорил ни буквально, ни не буквально.
Существует ли в реальном мире "два"?
А это тут при чем? Это оффтоп, мне неинтересно это обсуждать.
Вы сделали утверждение "Определения "сепулек" не существует без рекурсивности к изначальному определению".
Я сказал, что то определение, которое ссылается на изначальное, существует только в книге и начинается с "важный элемент цивилизации ардритов с планеты Энтеропия". В реальности нет никаких ардритов и планеты Энтеропия. Когда вы мне сказали это слово, вы не подразумевали цивилизацию ардритов. А что вы подразумевали? Вот это и будет определением этого слова в реальности, или по крайней мере его частью. И оно не рекурсивное. Пример выше на скриншоте.
Politura
Если включить режим подумать, то почти нормально отвечает:
Grad6
вот так тоже норм гпт выдает. да, по умолчанию модель пока не всегда определяет что надо подумать еще.
Sasha_Berg
Отличный ответ, хотелось проголосовать за, но дурацкий Хабр говорит, что мне надо вырастить карму. Вырастить карму, Карл! Для того, чтобы щёлкнуть по стрелочек вверх, дав понять, что мне нравится ответ?!
Этот баг покруче истории с перевернутой кружкой будет. IMHO
А нейронку, видимо, скорректировали. Или дообучили на подобных хитрых задачах.
1dNDN
Фича
ZudaR
Только что проверил. ChatGPT 5 Thinking
awaik