

Многие пользуются YouTube, Netflix, но не подозревают о ключевых опенсорсных программах типа ffmpeg, которые работают на бэкенде этих сервисов. Похожая ситуация с нейронками, где многие знают программу Ollama для локального запуска моделей на CPU. Но мало кто понимает, что это всего лишь простенькая оболочка вокруг опенсорсной библиотеки llama.cpp на С, которая и делает инференс. Автор этой библиотеки, талантливый разработчик Георгий Герганов, мало известен широкой публике.
Энтузиасты LLM в курсе, что происходит. Судя по всему, разработчикам Ollama выгодно нравится, что все лавры достаются им. Однако возникают странные ситуации, когда после выхода новой модели Ollama твитит «Работаем над поддержкой», хотя они просто ждут обновления llama.cpp.
Наверное, Георгия Герганова забавит такое поведение «бизнесменов от опенсорса». Хотя он скромный болгарский хакер и ни с кем особо не конфликтует.
В чём претензии к Ollama
Недавно Meta объявила о поддержке мультимодальности в LLama, поблагодарив в официальном блоге своих «партнёров в сообществе ИИ», в том числе Ollama, даже не упомянув llama.cpp.

Или вот недавно VSCode добавил поддержку локальных моделей в чате GitHub Copilot, упомянув оболочку Ollama, а не движок llama.cpp, который реально выполняет работу:

Георгий Герганов просто иронично упомянул этот факт, но не высказал претензий.
Сама Ollama тоже не упоминает авторов программного кода llama.cpp, а вот это уже является нарушением лицензии MIT.
Помимо этого, в сообществе LLM-энтузиастов в принципе недовольны политикой Ollama, которая ради хайпа делает некорректные рекламные заявления, создавая у широкой публики завышенные ожидания, что «каждый может запустить полноценную модель ChatGPT на своём телефоне», хотя на самом деле локально на ПК и смартфонах запускаются только совсем маленькие модели — и инференс очень медленный.
В результате пользователи недовольны, а крайними остаются разработчики моделей и llama.cpp.
Ещё Ollama в некоторых случаях некорректно именует модели, так что неполноценный дистиллят LLaMA с менее 10 млрд весов именуется как «просто» LLaMA. Это основная часть претензий к Ollama, которая гонится за хайпом, хотя бэкенд пишут другие.

Есть и другие проблемы:
Ollama не вносит значительных улучшений обратно в родительский проект. Да, они не обязаны это делать, но в качестве благодарности было бы нормально, если б они помогли
llama.cppс поддержкой мультимодальных моделей и внедрением инструментов вроде SWA (Sliding-Window Attention), это метод оптимизации внимания в LLM, позволяющий эффективно обрабатывать длинные последовательности без чрезмерных затрат на вычисления. Но Ollama предпочитает оставлять эти достижения при себе. Выходит новая модель — они твитят «Работаем над этим» и ждут, когда Георгий Герганов внедрит поддержку этой модели. По крайней мере, раньше такое было неоднократно.Плохие значения по умолчанию для запуска моделей. Преднастройки Ollama
сделаны якобы для удобства пользователей, но на практике они совершенно неразумно ограничивают функциональность llama.cpp:

Достаточно вспомнить размер контекста по умолчанию 2048 токенов, что было абсолютно неприемлемо для большинства задач. Сейчас его увеличили до 4096 токенов.
Для сравнения, конкуренты из LM Studio предлагают более продуманные настройки для продвинутых пользователей. И вообще, при наличии прокси типа LiteLLM для доступа к облачным моделям и llama.cpp для локальных — необходимость в Ollama вообще отпадает. Непонятно, зачем вообще использовать Ollama, если с оригинальной библиотекой идёт приятный локальный сервер llamacpp-server.
В целом, Ollama форкает различные опенсорсные проекты и пытается закрывать эти форки в своей экосистеме. Например, транспортный протокол Ollama — это форк открытого контейнерного протокола OCI (Open Container Initiative), но изменённый для несовместимости с DockerHub и др.
Собственно, и llama.cpp они просто форкнули и используют в своих целях, без обратной связи.
llama.cpp

Изначально llama.cpp создавалась как библиотека для инференса модели LLaMA от Meta на чистом C/C++. Работу над ней Герганов начал в сентябре 2022 года, после создания похожей библиотеки whisper.cpp для инференса модели распознавания речи ASR Whisper от OpenAI.
Разработка велась параллельно проекту GGML — универсальной библиотеки тензорной алгебры на C. Георгий говорит, что создание GGML было вдохновлено библиотекой LibNC от Фабриса Беллара.

Цель проекта — запуск моделей на компьютерах без GPU или других специализированных карт. С помощью llama.cpp современные LLM запускаются на обычных ПК и смартфонах Android. Хотя изначально библиотека писалась для CPU, позже была добавлена поддержка GPU.
В марте 2024 года другая известная хакерша Джастин Танни выпустила новые оптимизированные ядра для умножения матриц для x86 и ARM CPU, улучшив производительность FP16 и 8-битных квантизированных типов данных.
В нейросетях с пониженной точностью значения параметров (весов, смещений, активаций) кодируются 8-битными целыми числами (или ниже). Это позволяет значительно сократить объём памяти и ускорить вычисления, особенно на устройствах с ограниченными ресурсами.

Эти улучшения были внесены в llama.cpp. Танни также написала инструмент llamafile, который объединяет модели и llama.cpp в один файл, работающий на любых ОС.
На уровне библиотеки тензоров GGML в llama.cpp поддерживаются несколько платформ, включая x86, ARM, CUDA, Metal, Vulkan (версии 1.2 или выше) и SYCL. Вместо квантизации на лету llama.cpp выполняет предварительную квантизацию моделей. Для оптимизации используются несколько расширенных наборов инструкций: AVX, AVX2 и AVX-512 для x86-64, а также Neon на ARM.
Бинарные файлы GGUF (GGML Universal File) хранят и тензоры, и метаданные. Формат спроектирован для быстрого сохранения и загрузки данных модели, он был представлен в августе 2023 года для лучшей обратной совместимости, когда реализовали поддержку новых моделей.
GGUF поддерживает квантизированные целочисленные типы от 2 до 8 бит, распространённые форматы данных с плавающей запятой, такие как float32, float16 и bfloat16, квантизацию на 1,56 бита.
Другие проекты Герганова
whisper.cpp: высокопроизводительный инференс модели ASR Whisper от OpenAI на CPU с использованием C/C++.
GPT-J: инференс на CPU с использованием C/C++.
slack (tui): текстовый UI для клиента Slack | исходники | видео0 | видео1.
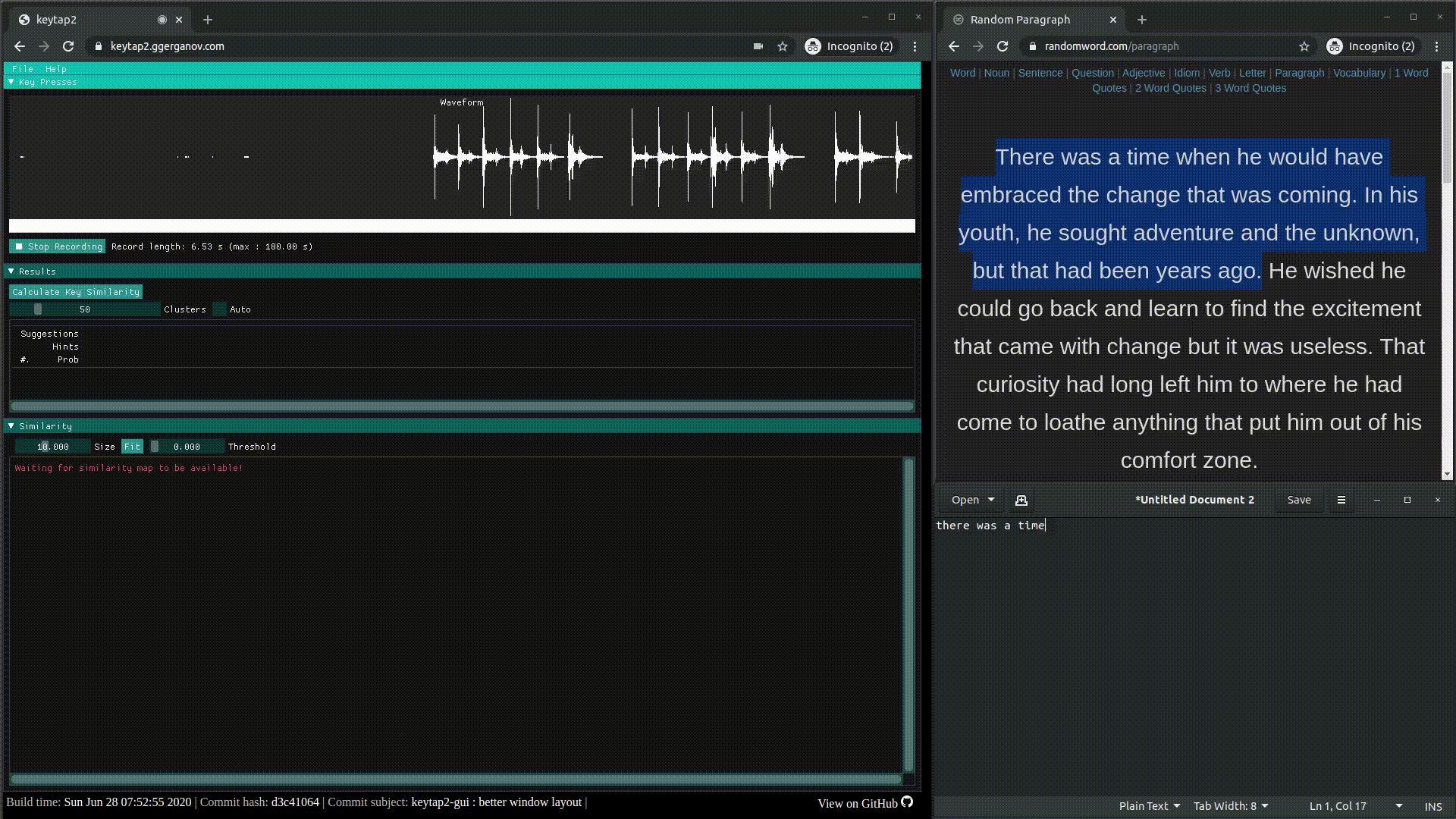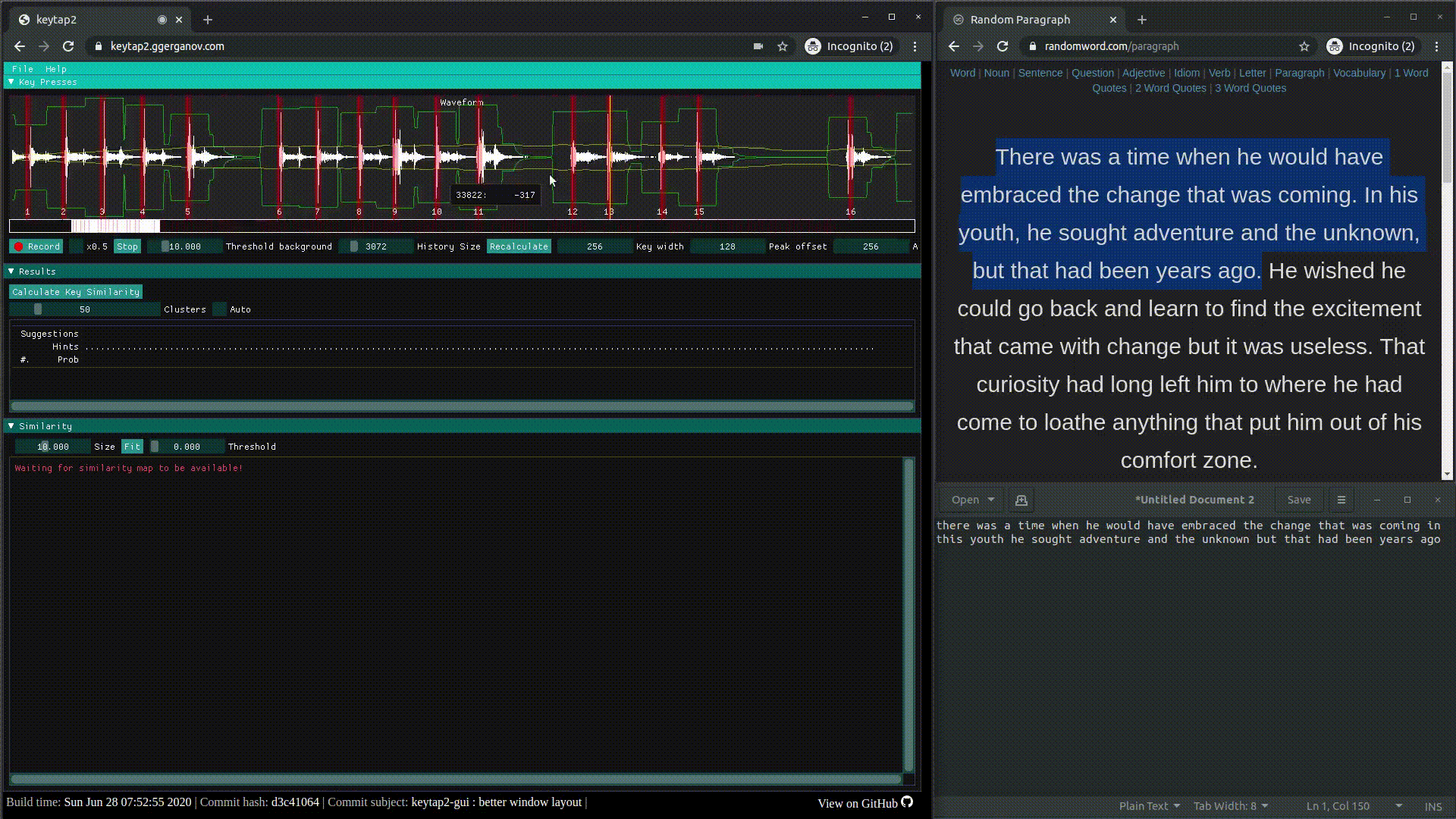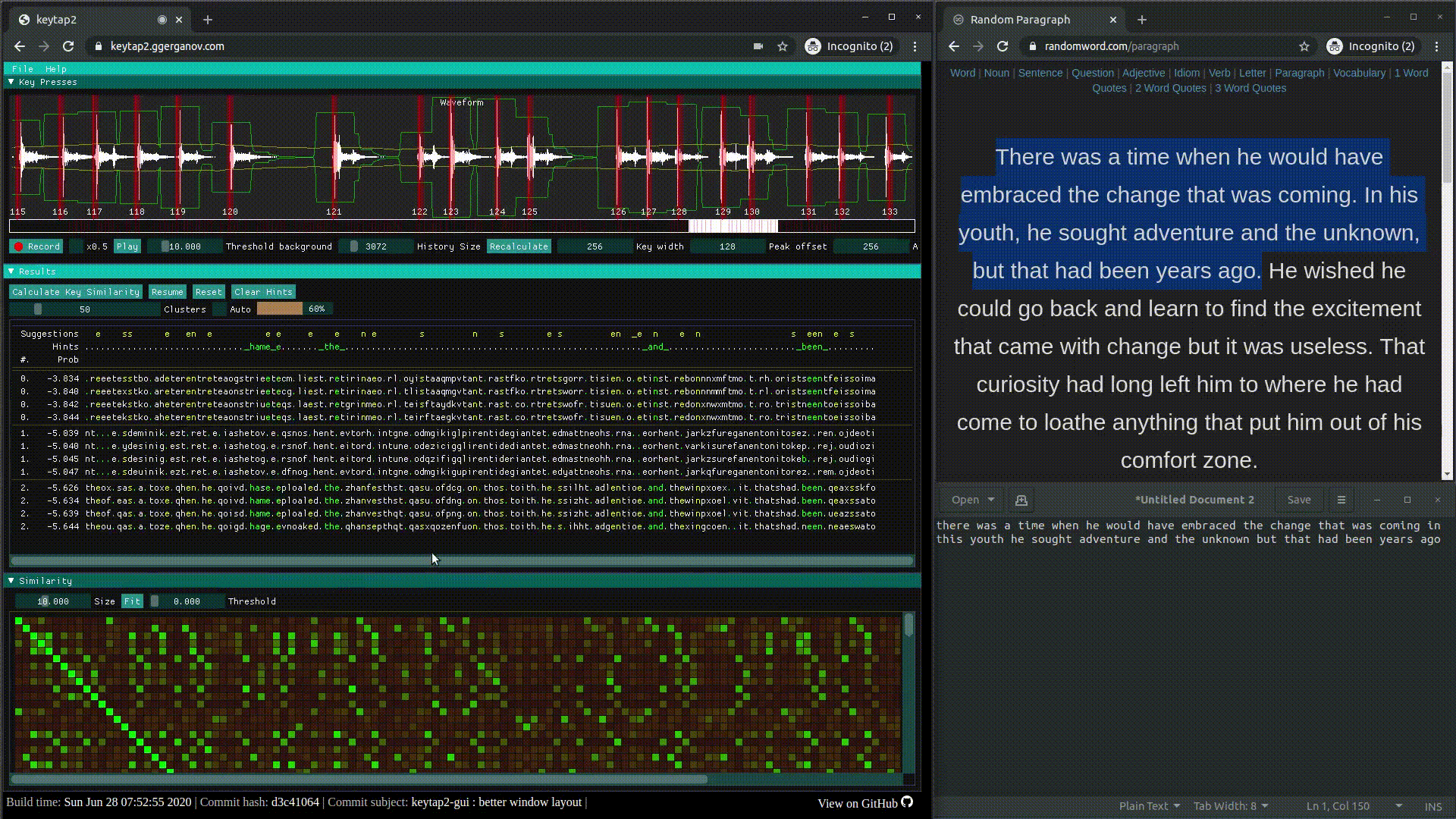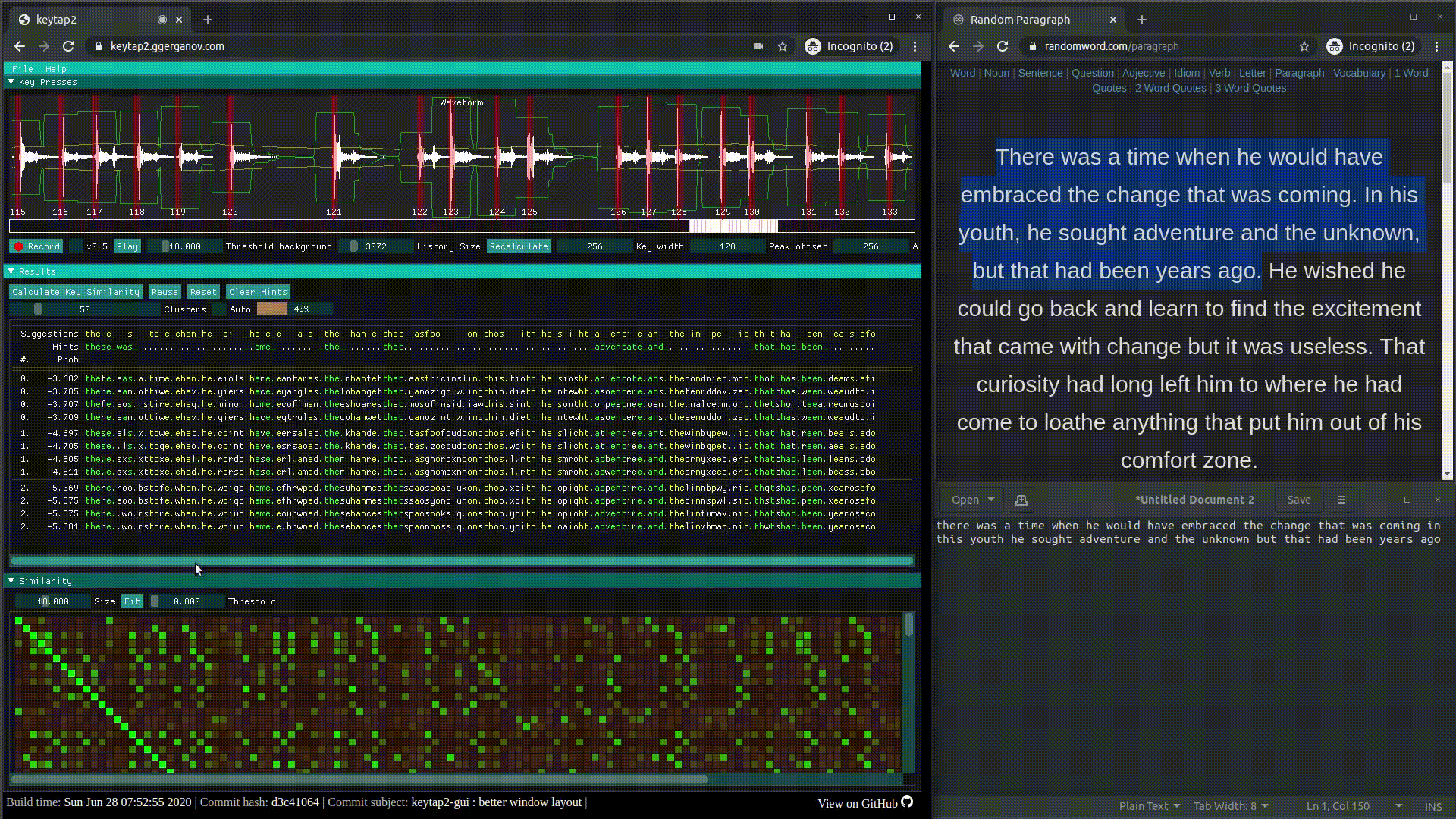
keytap3: прослушка клавиатуры из браузера через микрофон | исходники | gui.

the-story: эксперимент по коллективному написанию текста большим количеством авторов (с голосованием за слова) | исходники.
@tweet2btc: коллективное предсказание цены биткоина через опросы в Twitter | исходник.
@tweet2doom: твиттер-бот, который играет в Doom | исходники | данные | эксплорер.

morse-meme: генератор мемов на азбуке Морзе | исходники.
GGMorse: расшифровка кода Морзе в реальном времени по звуку| исходники | iOS | Android.

Spectrogram: визуализация аудиоспектра в реальном времени | исходники.
Waver: обмен сообщениями и файлами по звуковому каналу (через ультразвук) | исходники | iOS | Android.

Это удобный способ передать файлы с одного мобильного устройства на другое, если они не могут установить цифровое соединение.
keytap2: звуковой кейлогер на основе частотных n-грамм, то есть комбинаций из последовательностей звуковых фрагментов | исходники | обсуждение.

(https://asciinema.org/a/310405)
ImTui: библиотека непосредственного режима (immediate mode) в текстовом UI | исходники на C++. Она используется в текстовых клиентах для Slack, WTF и HN, которые указаны выше в этом списке проектов.

dot-to-ascii: Конвертер Graphviz в ASCII | исходники.

lottery-check: показывает, как часто выигрывали произвольные комбинации чисел в болгарской лотерее 6/49 | исходники.
Diff Challenge: игра Diff Challenge в виде баш-скрипта, смысл игры заключается в поиске программы
y, которая изменяет программуx, а выдачаyсоответствует разнице междуxиy:
$ ./y > diff
$ patch y < diff
$ cmp x y
$
ImGui-WS: графический интерфейс Dear ImGui через WebSockets | исходники.

typing-battles: многопользовательская игра, кто быстрее набирает на клавиатуре (сервер: C++/WebSockets, клиент: JS) | исходники.
keytap-challenge: угадай, какой текст набирается.
keytap: акустическая прослушка клавиатуры с предварительным обучением.
wave-gui: ещё один инструмент передачи данных с помощью звука | исходники.
wave-share: передача файлов с помощью звука через браузер | исходники.
© 2025 ООО «МТ ФИНАНС»
Комментарии (37)

programania
07.07.2025 12:52Исходный текст llama.cpp - 25 мб.
И похоже Releases обновляется несколько раз каждый день уже года 2.
За 11 минут компилируются в llama-server.exe+dll - 76 мб.
Для python torch и пр. нужно около 5 гб. т.е. в 50 раз больше!
При этом llama.cpp содержит web интерфейс и ещё кучу полезных программ.
Почему такая разница?Для себя сделал интерфейс на Delphi к llama-server и whisper.cpp.
При этом контроль намного больше, чем у прочих оболочек
и можно сделать всё как мне нужно.А gguf - уже стал стандартом для локальных LLM и любая программа, которая его загружает, использует llama.cpp.

Kromster80
07.07.2025 12:52"Интерфейс на Delphi к llama-server и whisper.cpp." - можете рассказать поподробнее с какими целями и что получается?
programania
07.07.2025 12:52Для контроля вывода - IdHTTP с IdHTTP1ChunkReceived и "stream":true позволяет
получать ответ по токенам и останавливать при повторах, числу предложений,
максимальному размеру списка и т.п и говорить голосом по предложениям.Для автоматизации запросов: можно получить несколько ответов и выбрать лучший
или автоматически формировать новые запросы из ответов или просто
запрашивать "Продолжай мыслить и саморазвиваться." и сделать
мышление LLM бесконечным.
Для оценки моделей: выдать несколько запросов из списка и оценить ответы
по наличию полезных для меня слов.Для контроля запроса: системный промпт + указанное число вопрос-ответ диалога + промпт + теги
по шаблону. Причем диалог можно редактировать, отменять, повторять, запоминать, т.к. он в RichEdit и его можно подчищать, форматировать, раскрашивать.whisper.cpp реализовал, работает, но не использую - надо микрофон, наушники, клавишами удобнее.
И ещё много идей пробовал и буду пробовать.
Со своей программой этому ничто не мешает.

413x
07.07.2025 12:52В опенсорс не выкладывали свой интерфейс?
programania
07.07.2025 12:52В опенсорс не выкладывал.
Когда-нибудь выложу, но для этого нужно подчищать, писать справку.
Там многие настройки прямо в программе - мне просто, а люди не поймут
и много остатков реализаций моих идей, что усложнит понимание.
Может просто как пример работы с llama-server из Delphi.

QtRoS
07.07.2025 12:52Почему такая разница?
Потому что сначала трансформеры нужно было открыть, т.е. обнаружить эту успешно работающую на практике модель с помощью многих итераций проб и ошибок. И только потом стало возможным написать эффективную реализацию на C/C++, зная что нужно написать и имея готовые веса для проверки.
Python'овский ML-стек подходит для исследователей, так как даёт высокую скорость итераций и лёгкость экспериментирования. C/C++ же даёт скорость выполнения за счёт эффективной реализации конкретной модели.


Gordon01
07.07.2025 12:52В этом нет ничего удивительного. Людям нужен продукт.
Что мешает автору llama.cpp упаковать свою библиотеку в красивую коробку, которая легко устанавливается и имеет удобный UI?
Вопрос риторический, но ответ скорее всего: он этого сделать не может. Потому что не имеет продуктового мышления.
А продуктовом мышление, способность не только прекратить свои идеи в рабочий код, а ещё и сделать так, чтобы код решал нужную людям проблему - искусство.
Людям не нужна библиотека для инференса на ЦПУ или ГПУ, людям нужна программа чтобы запускать локально ЛЛМки. Ollama и LM toolbox решают эту проблему. llama.cpp - нет

checkpoint
07.07.2025 12:52Похоже что автор статьи "слышал звон". llama.cpp это давно уже не просто библиотека, а целая система с кучей плагинов и собственным Web сервером с поддерждкой различных API. Установка llama.cpp выглядить до боли тривиальна:
cmake . && make install. Установка моделей полность автоматизирована, просто указываете название модели и он выкачивает её с Huggingface и запускает. Какое еще нужно продуктовое мышление ?$ git clone https://github.com/ggml-org/llama.cpp.git $ cmake . $ make && make install # далее $ llama-cli --help # Web сервер с чатом можно запустить вот так: $ llama-server -m $MODEL --host 1.2.3.4 --port 8080 # далее подключаетесь Web браузером на 1.2.3.4:8080 и получаете # полноценный интерфейс к ИИ чат-ботуИ да, llama.cpp поддерживает FIM API позволяя подключать vim, vscode и прочие IDE.
Мы держим свой локальный сервер на базе llama.cpp с моделями DeepSeek для чата и для FIM. Спасибо Георгию за то, что сделал инферренс моделей простым и доступным для старпёров умеющих в make.
Что такое Ollama - понятия не имею. Очень похоже, что это еще одни паразиты из лагеря питонистов. В который раз убеждаюсь, что питонисты без поддержки сишников и плюсоводов ничего толком сделать не могут, только обертку красивую нарисовать и вперед - клянчить деньги инвесторов. На Hacker News таких добрая половина, а в составе YC - все 100% стартапов.

iroln
07.07.2025 12:52Установка llama.cpp выглядить до боли тривиальна:
cmake . && make installАга, тривиальна, если не лезть в CMakeLists и не смотреть какие опции там используются, что включено по умолчанию и какие там зависимости, какие оптимизации и т. д. Пакетные менеджеры существуют уже несколько десятков лет, а кто-то до сих пор считает, что
cmake . && make install- это нормальный способ установки пользовательского ПО в операционной системе. Может хватит уже? Шутка надоела.
А с pre-built у них так себе, не каждый захочет пользоваться nix.
p07a1330
07.07.2025 12:52, если не лезть в CMakeLists и не смотреть какие опции там используются
А зачем?
Или вы когда условный npm i запускаете - тоже все дерево зависимостей отсматриваете?iroln
07.07.2025 12:52Ну хотя бы затем, чтобы понимать, что там вообще происходит, потому что в cmake конфиг можно напихать всё что угодно и install-цели можно тоже определить как угодно.
npm не запускаю, но дерево зависимостей пакетов смотрю. Хорошая привычка, я считаю. Это вообще давно проблема - распухающие зависимости.

Uporoty
07.07.2025 12:52А зачем?Или вы когда условный npm i запускаете - тоже все дерево зависимостей отсматриваете?
npm (без опции -g) ставит все пакеты в локальную папку, а make install без должного контроля легко устраивает срач в системе, который потом еще и не вычистить так просто.

hogstaberg
07.07.2025 12:52это нормальный способ установки пользовательского ПО в операционной системе
В случае комплексного, не всем нужного ПО, которое нередко требуется собрать под свои личные нужды - да, cmake + make + закатать в свой собственный пакет - это абсолютно нормальный способ.
iroln
07.07.2025 12:52`make install` ненормальный способ, потому что пока ты не залезешь в конфигурацию cmake или в сгенерированный makefile и не посмотришь как прописаны install-цели, ты вообще не знаешь, что он сделает и куда распихает весь хлам.
Сборка под свои личные нужды - это вообще отдельный случай, и там как раз придется лезть в cmake конфиг и разбираться с опциями сборки. Это вообще не способ установки ПО в систему.hogstaberg
07.07.2025 12:52cmake + make + закатать в свой собственный пакет
Ткните, пожалуйста, в "make install". А то я слепой, найти не могу.
Uporoty
07.07.2025 12:52закатать в свой собственный пакет
так выше речь идет как раз не про закатывание в пакет, а про тупо install скриптом глобально в систему.
checkpoint
07.07.2025 12:52Ага, тривиальна, если не лезть в CMakeLists и не смотреть какие опции там используются,
Во-первых, в CMakeLists смотреть не надо, надо читать README.md, это если Вас интересуют какие-то специализированные опции. Во-вторых, там подефолту всё нормально отстроено, никаких опций крутить не требуется. Инструкция, которую я привел выше, рабочая! cmake автоматом подхватывает CUDA если он у Вас есть и собирает всё что требуется. Я вот буквально вчера запустил llama.cpp на RTX 4060, никаких опций не накручивал.
При запуске llama-server пришлось, правда, ограничить число слоёв для оффлоада на GPU (-ngl 20) из-за малого обьема VRAM памяти на карточке.

turbotankist
07.07.2025 12:52Go-шники.
Ну нормальная тулза - запустить ллм, если ты не хочешь вообще ничем заморачиваться. Как продукт они, конечно, обычному пользователю тоже не упали.

vcKomm
07.07.2025 12:52За свой небольшой опыт с линуксом, если я вижу
make, я до победного ищу готовые бинарники. Потому что обязательно что-то разломается и сиди несколько часов кури гугл.Ollama в ридми даёт ссылки на готовые dmg/exe файлы, чтобы даблклик и все готово
checkpoint
07.07.2025 12:52За свой небольшой опыт с линуксом, если я вижу make , я до победного ищу готовые бинарники.
Какой-то у Вас неправильный опыт. Если я вижу Makefile, то беру и собираю из исходников. Я вообще стараюсь держать всё в исходниках, кроме компилятора. Как раз потому, что когда-то их обязательно сломают и я смогу откатиться на требуемую мне версию (может быть даже исправить проблему самостоятельно), а не судорожно искать и качать новые бинарники ко всему стеку используемого софта со всеми его зависимостями.

DrArgentum
07.07.2025 12:52Что такое Ollama - понятия не имею. Очень похоже, что это еще одни паразиты из лагеря питонистов. В который раз убеждаюсь, что питонисты без поддержки сишников и плюсоводов ничего толком сделать не могут, только обертку красивую нарисовать и вперед - клянчить деньги инвесторов. На Hacker News таких добрая половина, а в составе YC - все 100% стартапов.
По большей частью хорошие питонисты - хорошие сишники.

EugeneH
07.07.2025 12:52Никогда не пользовался Ollama. Это такой же полуфабрикат как и llama.cpp, только еще и скачает непонятно что непонятно откуда за тебя.
Долгое время хватало llama.cpp-python и своих надстроек для RAG и других вещей. Потом стало интересно экспериментировать с activation steering, выбором из словаря, и прочим, что не было на тот момент реализовано в llama.cpp. В итоге перекатился на hugging face transformers, хоть она и не позволяет разбивать веса между GPU и СPU (по крайней мере я не знаю как).
checkpoint
07.07.2025 12:52Я думал, что Георгий Герганов наш соотечественник, оказывается - потомственный болгагин. :-)

Wesha
07.07.2025 12:52Хотите сказать, что Киркоров Вас ничему не научил?



maxcat
07.07.2025 12:52>в llama.cpp поддерживаются несколько платформ, включая x86, ARM, CUDA, Metal, Vulkan (версии 1.2 или выше) и SYCL
Даже какие-то ограниченные вендором metal и cuda есть, а единственно верного Dx нет что-ли?

Shushpancheak
07.07.2025 12:52iSWA (Integrated Service Workload Analyzer), который представляет аналитику о рабочей нагрузке
Нет, это Interleaved Sliding Window Attention, он уменьшает размер kv-кэшей для длинных контекстов
Wesha
07.07.2025 12:52Попробовал этот "звуковой кейлоггер" — полная буйня на постном масле. Не говоря уж о том, что прямо в документации сказано, что рассчитан только на английский язык — так ещё и, судя по всему, на тех, кто сидит в звукоизолированной комнате, никогда при печати не затыкается и не делает опечаток.

BadNickname
07.07.2025 12:52Вы всегда можете помочь и собрать больше данных для датасета для дообучения.
dpbm
Интересно было примерить этот dot-to-ascii для наших схем, спасибо!
https://habr.com/ru/companies/yoomoney/articles/830538/