
Меня зовут Мария Жарова, я ML-инженер в Wildberries, преподаватель и автор канала Easy Data. Давайте разберемся, где и зачем дата-сайентисту нужна линейная алгебра. Не будет скучных доказательств, только практические примеры, визуализация и конкретные кейсы.
Поехали!

Я была уверена, что линейная алгебра осталась где-то между зачетом и пыльным конспектом. Но оказалось, что в Data Science без нее никуда.
Знакомо? Многие приходят в анализ данных ради практики: прогнозировать спрос, строить рекомендательные системы, запускать модели в прод. Но внезапно оказывается: за большинством инструментов, с которыми дата-саентисты работают каждый день, скрываются векторы, матрицы, собственные числа и линейные преобразования — забытые, как страшный сон.
Важно понимать: Data Science — это не только математика. Но без нее не получится разобраться, как все работает. Вы можете стартовать, просто используя готовые библиотеки. Но чтобы перейти от «новичка с питоном» к инженеру, который понимает, что происходит внутри моделей и почему они работают (или не работают), без базовых знаний линейной алгебры не обойтись.
Что такое линейная алгебра на деле
Вспомним основные определения из линейной алгебры, но на примере понятий из Data Science, с которыми мы работаем каждый день.
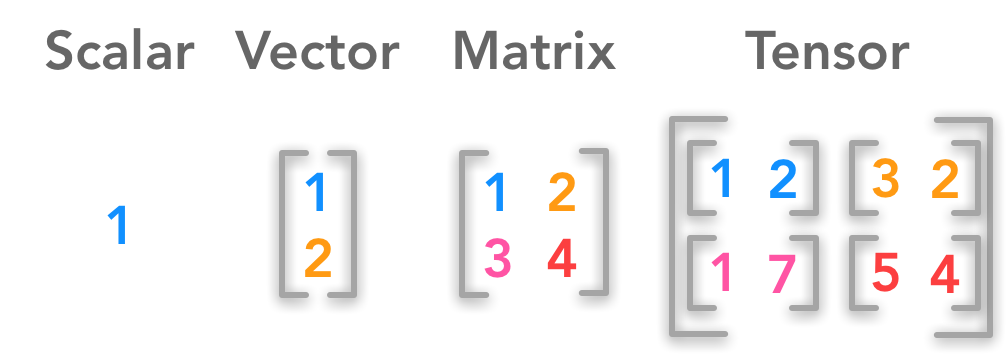
Векторы
Вектор — это просто направленный отрезок в пространстве. А в машинном обучении это в первую очередь:
признаки объекта ([рост, вес, возраст]);
эмбеддинги объектов: слов, картинок, товаров, клиентов… ([0.3, -0.5, 0.8, ...]);
веса модели ([w1, w2, w3, ...]).
По сути, почти все в ML-моделях — это векторы.
Напомним: два вектора считаются равными, если они имеют одинаковую длину и направлены в одну сторону. Это удобно, если мы описываем объект, — например, текст или изображение — вектором (или эмбеддингом). Если два таких вектора почти совпадают, это значит, что и объекты, которые они представляют, очень похожи.

Тут же можно вспомнить про такое свойство, как линейная (не)зависимость векторов. Оно означает, что один вектор можно (или нельзя) выразить через другие с помощью обычных линейных комбинаций (сложения и умножения на числовой коэффициент).
Линейная комбинация векторов — это выражение вида:

где  — заданные векторы,
— заданные векторы,  — числовые коэффициенты (скаляры).
— числовые коэффициенты (скаляры).
Набор векторов называется линейно зависимым, если хотя бы один вектор можно выразить как линейную комбинацию остальных.
Набор векторов называется линейно независимым, если ни один вектор из набора не выражается как линейная комбинация остальных.
Это свойство играет ключевую роль в анализе данных — например, если в наборе признаков есть линейно зависимые, значит, они содержат избыточную информацию. Это может привести к переобучению модели или численной нестабильности при обучении.
Матрицы
Тут тоже все просто: матрицы — это таблицы чисел. Несколько примеров из DS:
датафрейм: объекты — строки, признаки — столбцы;
матрица покупок пользователь-товар;
набор весов нейронной сети между слоями.


Набор векторов можно собрать в матрицу — и работать с ними сразу с помощью матричных операций. Эту идею можно продолжить: составить «вектор из матриц», «матрицу из матриц» — все это будет называться тензором.

Например, представление цветного изображения в виде трех каналов RGB — трехмерный тензор:

Из важных свойств на этом этапе отметим ранг матрицы. Он показывает, сколько строк (или столбцов) в матрице линейно независимы. По сути, это сколько «информации» содержится в ней. Если признаки в датасете сильно коррелируют между собой, ранг матрицы может оказаться ниже количества признаков. Это значит, что часть данных избыточна, и модель может начать «заучивать» шум. Данный эффект наблюдается при переобучении.
Ранг играет ключевую роль и в других задачах. Например, в методах сжатия данных или восстановлении пропущенных значений мы стремимся найти приближение исходной матрицы с меньшим рангом. Так работает SVD в рекомендательных системах или LSA в обработке текстов.
Линейные преобразования (операторы)
Вот тут уже поинтереснее. Линейное преобразование — это функция, которая:
сохраняет прямые (если на входе — прямая, то и на выходе тоже прямая);
сохраняет начало координат
 ;
;подчиняется законам:
 .
.
Важное наблюдение: каждое линейное преобразование — это просто умножение на матрицу.
Линейное преобразование может растягивать, сжимать, поворачивать или отражать вектор в пространстве. Вот несколько интуитивных примеров:
Преобразование |
На какую матрицу умножить |
Увеличение в 2 раза по оси |
[[2, 0], [0, 1]] |
Отражение относительно оси |
[[-1, 0], [0, 1]] |
Поворот на 90° |
[[0, -1], [1, 0]] |
Проекция на ось |
[[1, 0], [0, 0]] |



{kind=link}
{kind=link}
Возьмите любой двумерный вектор, умножьте на эти матрицы — и увидите, как он изменится:

Оставаясь в теме линейных преобразований, вспомним другие ключевые понятия в линейной алгебре: собственные векторы и собственные значения.
Если при линейном преобразовании (то есть умножении на матрицу) вектор не меняет свое направление — это собственный вектор.
Коэффициент, на который он при этом растягивается или сжимается, называется собственным значением.
Это важное свойство позволяет анализировать структуру самого преобразования: понять, какие направления устойчивы и как сильно они масштабируются. Именно на этом основаны такие методы, как PCA или спектральная кластеризация.
А при чем тут ML? И линейные преобразования, и собственные числа регулярно встречаются в машинном обучении:
PCA (метод главных компонент): ищет такое линейное преобразование, которое спроектирует данные на «наиболее информативные» оси — это про повороты и проекции.
Нейросети: каждый слой — это линейное преобразование
 , за которым идет нелинейность (например, в виде функции активации).
, за которым идет нелинейность (например, в виде функции активации).Градиенты: вычисление производных по вектору — линейная операция.
Эмбеддинги: перевод объектов из одного векторного пространства в другое — это линейное преобразование.
Подведем итог:
Линейная алгебра — язык работы с многомерными данными.
Линейные преобразования — инструмент, чтобы понять, как данные трансформируются.
При умножении матрицы на вектор матрица превращается из таблицы в оператор, который действует на векторы. Именно с этим мы сталкиваемся на каждом шаге обучения модели.
Где линейная алгебра встречается в Data Science и ML
Теперь, когда мы вспомнили, что такое векторы, матрицы и линейные преобразования, пора перейти к конкретным примерам — где вся эта математика действительно используется в реальных задачах.
Векторы как способ измерить смысл
Один из самых наглядных примеров линейной алгебры — это векторные представления (embeddings или эмбеддинги). С их помощью тексты, картинки, пользователи, товары, фильмы и все что угодно превращаются в векторы в многомерном пространстве, сохраняя при этом смысловые отношения.
Многие слышали про Word2Vec и GloVe — методы, которые преобразуют слова в векторы так, что смысловые отношения становятся линейными. Позже появились FastText (учитывает морфологию слов), ELMo (контекстные эмбеддинги), а затем и трансформеры вроде BERT, GPT, RoBERTa — модели, где каждое слово получает контекстно-зависимый вектор.
Общие принципы сохраняются: векторизация, измерение сходства, линейные операции — все это основано на фундаментальных идеях линейной алгебры.
Итак, идея простая: каждое слово — это точка в высокоразмерном пространстве (например, 300-мерном). Координаты подбираются так, чтобы:
близкие по смыслу слова имели близкие векторы;
отношения между словами выражались векторами.
Иными словами, создается линейное пространство смыслов.
Чтобы измерить, насколько похожи два слова, мы считаем косинусное сходство между их векторами:

Это простое скалярное произведение нормированных векторов — базовая операция из линейной алгебры. Она отлично работает для семантики: «кошка» ближе к «собаке», чем к «яблоку».
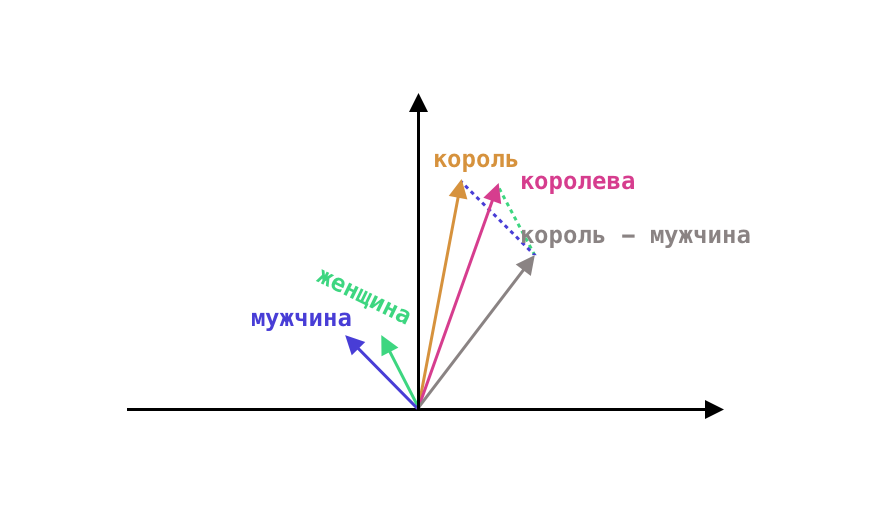
Рассмотрим эффект «близких слов» на популярном примере «король - мужчина + женщина ≈ королева». В векторном пространстве Word2Vec можно взять вектор «король», вычесть вектор «мужчина», прибавить вектор «женщина» и получить результат, близкий к вектору «королева»:
vec("король")−vec("мужчина")+vec("женщина")≈vec("королева")vec("король")−vec("мужчина")+vec("женщина")≈vec("королева")

{kind=link}
Это работает потому, что линейные отношения между словами сохраняются в этом пространстве. Векторы слов образуют линейные направления для таких понятий, как «пол», «степень» и т. п.
Похожий пример был на картинке в прошлом разделе для огурца, яблока и апельсина: только там мы рассматривали «направления» цвета, сладости и формы.
Это возможно, потому что при обучении любого ML-алгоритма решается задача оптимизации (минимизация функции потерь), которая в итоге приводит к формированию векторов, уважающих линейные зависимости между контекстами. Это не магия, это — линейная алгебра + стохастический градиентный спуск.
Ранг матрицы, корреляции и численная нестабильность
Работая с табличными данными, вы наверняка сталкивались с ситуациями, когда:
признаки подозрительно похожи друг на друга;
модель нестабильно обучается;
веса в линейной регрессии уходят в бесконечность.
Часто причина в низком ранге матрицы признаков.
Ранг матрицы — это количество линейно независимых столбцов (или строк).
Если одни признаки выражаются через другие (например, один — это сумма или масштаб копии двух других), то ранг становится меньше числа признаков.
Вот почему это важно:
-
Вырожденная система: линейные модели (регрессия, логистическая регрессия), по сути, решают переопределенные системы уравнений. При линейной зависимости между признаками система становится неустойчивой — решений может быть много или они чувствительны к шуму.
 — формула для решения переопределенной системы линейных уравнений
— формула для решения переопределенной системы линейных уравнений  методом наименьших квадратов (МНК). По сути, это реализуется в sklearn.LinearRegression.
методом наименьших квадратов (МНК). По сути, это реализуется в sklearn.LinearRegression. Мультиколлинеарность: модель не может понять, какой признак важнее. Это приводит к скачкам весов и переобучению.
Теперь посмотрим, что с этим можно сделать. Джентльменский набор при ответе на вопрос: «Как бороться с переобучением классических ML-алгоритмов»:
Удалить сильно коррелирующие признаки (именно из-за них ранг матрицы снижается).
Использовать регуляризацию (L1 или L2) — она делает систему более устойчивой (т. к. штрафует за слишком большие веса).
Применить низкоранговое приближение (SVD, PCA) — убрать шум и оставить главное. Ну или сделать отбор признаков теми же встроенными SelectKBest или CatBoost Feature Seletor.
Низкий ранг — не всегда проблема. Это подсказка, что данные можно сжать и упростить без потери сути.
Метод главных компонент (PCA)
Метод главных компонент (Principal Component Analysis, PCA) — это базовый метод снижения размерности через линейное преобразование. Он переопределяет систему так, чтобы:
новые оси (главные компоненты) указывали в направлении наибольшей изменчивости данных;
каждая следующая компонента была ортогональна предыдущей;
можно было отбросить «наименее важные» оси и тем самым снизить размерность без сильной потери информации.
Как работает:
Строится ковариационная матрица признаков (а это обычная матрица).
Вычисляются собственные векторы и собственные значения этой матрицы, то есть направления, в которых данные «разбегаются» сильнее всего.
Собственные векторы образуют новое ортонормированное базисное пространство.
Исходные данные проецируются на это пространство — это и есть линейное преобразование.

Другими словами, собственные векторы — это новые оси, а собственные значения — исперсия вдоль этих осей.
Метод широко применяется в предобработке данных для удаления лишних признаков и шума, для визуализации — переводит многомерные данные в 2D или 3D, чтобы можно было наглядно увидеть их структуру и зависимости (например, после кластеризации), ну и для ускорения обучения и повышения устойчивости моделей.
Обучение нейросети — это перемножение матриц
Если вы когда-нибудь обучали нейросеть (пусть даже самую простую), вы уже работали с линейной алгеброй. Просто не всегда это заметно, так как за вас все делает PyTorch, TensorFlow или Keras.
Нейросеть — это последовательность линейных преобразований, комбинируемая с нелинейными:
Например:  →
→  →
→  →
→  →
→  → ... →
→ ... →  , где:
, где:
 — матрица весов на i-м слое;
— матрица весов на i-м слое; — вектор смещений (bias);
— вектор смещений (bias); ,
,  ,
,  — нелинейные функции активации.
— нелинейные функции активации.
Получается, Forward pass — это обычное перемножение матриц, т. е. когда мы «прогоняем» вход через сеть, мы:
Берем вектор признаков
 .
.Преобразуем его с помощью весов (
 ).
).Применяем активации.
Повторяем шаги 2–3 на следующем слое.
При обучении же, а именно, на этапе Backpropagation, добавляются транспонированные матрицы, производные и градиенты (но мы помним, что градиент — тот же вектор).
Вся магия нейросетей — это поиск таких матриц весов  , которые хорошо приближают функцию из
, которые хорошо приближают функцию из  в
в  . Чем эффективнее мы считаем и обновляем эти матрицы, тем лучше учится сеть, поэтому в основе любых оптимизаций лежат операции линейной алгебры.
. Чем эффективнее мы считаем и обновляем эти матрицы, тем лучше учится сеть, поэтому в основе любых оптимизаций лежат операции линейной алгебры.
Свертки в компьютерном зрении
Сверточные нейросети (CNN) сделали революцию в распознавании изображений. Они успешно определяют объекты, сегментируют сцены, распознают лица. Но что такое свертка?
На практике свертка — это операция над матрицами:
Берем изображение как матрицу чисел (яркость пикселей).
Берем ядро свертки — маленькую матрицу (например, 3×3).
-
Скользим по изображению и считаем скалярное произведение ядра и соответствующего окна.


Вариант свертки
Если говорить про свертку с фиксированным ядром, то это просто линейный фильтр, заранее заданный вручную. Такие фильтры используются в классическом компьютерном зрении для решения типовых задач:
фильтр Собеля — выделяет границы, усиливая резкие изменения яркости по горизонтали или вертикали;
Гауссов фильтр — сглаживает изображение, устраняя шум;
Лапласиан — усиливает контраст и выделяет контуры второго порядка.

Фиксированные фильтры не обучаются, но позволяют извлекать локальные шаблоны (градиенты, края, текстуры) из изображения с помощью простых линейных операций. Это хорошая интуитивная база перед изучением обучаемых сверток в CNN.
Если ядро обучается, как в CNN, то нейросеть сама учится «видеть» края, текстуры и объекты, подбирая нужные фильтры. И все это — линейные преобразования.
Заключение
Линейная алгебра в ML — это не «учебник», это инструмент. Это язык, на котором говорят модели, алгоритмы снижения размерности, методы поиска смыслов и связей в данных.
Вам не обязательно превращаться в математика-теоретика и доказывать теоремы, чтобы стать отличным дата-сайентистом. Но понимание базовых концепций — что делает матрица, зачем нормализуют вектор, как устроено пространство признаков — помогает быть не просто программистом, а специалистом Data Science, способным принимать эффективные и обоснованные решения, быстро находить и устранять проблемы при работе с конкретными датасетами.
А главное — видеть в моделях не черный ящик, а работающий инструмент, которым можно управлять осознанно.
Автор: Мария Жарова — ML-инженер в Wildberries, преподаватель и автор канала Easy Data, гостевой эксперт онлайн-магистратур Центра «Пуск» МФТИ.
Комментарии (3)

Liugger
16.07.2025 10:13Хорошая обзорная статья, полностью согласен с выводами. Я бы еще добавил, что специалисту по DS полезно было бы еще освоить операции линала в numpy - порой помогает писать значительно более быстрый код
ChePeter
Такая алгебра точно не нужна. У Вас подразумевается евклидово пространство и тривиальная операция сложения. Это хорошо для простых случаев, но они и так хорошо изучены. А в большинстве современных задач будете так складывать тёплое с мягким или 1.5 землекопа + 0.5 землекопа у Вас получится 2 землекопа.
Liugger
Сложно понять, что вам не понравилось в "такой алгебре". Я не против складывать 1.5 + 0.5 землекопа. В общем-то и теплое с мягким, когда это два вектора, превращенные линейной комбинацией в главную компоненту с интерпретацией 'комфорт".
Приведите пример другой алгебры полезной в прикладном смысле, относительно data science (это ведь тема статьи)
Автор не врет, когда говорит что специалисту в Data science без знания таких концепций не стать настоящими профессионалом.
Сам как аналитик данных подтверждаю, что даже базовое понимание линейной алгебры очень хорошо прокачивает спеца.
А если говорить про инетпретируемый анализ данных, то более сложная математика зачастую противопоказана