
Если вы когда-либо работали с облачными LLM, то наверняка испытывали это странное чувство: вроде бы создаешь что-то свое, но по факту остаешься гостем в чужом доме. Можно сравнить это с заказом еды из модного ресторана: невероятно удобно, быстро и, как правило, вкусно, но ты не контролируешь ни качество ингредиентов, ни процесс их приготовления. Запуск LLM на своем железе — это, в моем понимании, переход от статуса гостя к владельцу собственной, профессионально оборудованной «AI-кухни». Сразу оговорюсь: это не «серебряная пуля» и не универсальное решение для каждого. Но для определенных задач и конкретных групп пользователей оно становится не просто предпочтительным, а единственно верным.
Проанализировав десятки дискуссий в сообществе и изучив технические отчеты, я пришел к выводу, что в 2025 году локальный AI — это в первую очередь инструмент для тех, кто ценит суверенитет, контроль и эффективность. Чтобы понять, для кого именно эта игра стоит свеч, я разделил всех адептов локального запуска на четыре большие группы.
Первая и самая очевидная — это, конечно, разработчики и IT-специалисты. Для нас с вами локальный LLM — это не игрушка, а мощный рабочий инструмент, еще одна утилита в арсенале. Судя по обсуждениям, модели, заточенные под код, такие как Qwen3-Coder или DeepSeek Coder, используются для быстрого написания бойлерплейта, отладки сложных участков, прототипирования новых фич и вайбкодинга. И все это — без ежемесячных счетов за каждый отправленный токен и без зависимости от внешнего API. Это не только экономит деньги, но и делает рабочий процесс более гибким, предсказуемым и, что немаловажно, быстрым.
Вторая группа, которая, как мне кажется, является главной движущей силой всего этого движения, — это энтузиасты и исследователи. Я сам часто сижу в сабреддите r/LocalLLaMA, и это место — настоящий плавильный котел идей. Эти люди — не просто пассивные потребители технологии. Они активно участвуют в создании экосистемы: экспериментируют с новыми моделями, изучают их архитектуры, дообучают их для своих уникальных, порой совершенно неожиданных нужд. Именно благодаря их любопытству и упорству мы получаем подробные тесты производительности, гайды и новые способы применения AI.
Третья категория, чья важность в мире тотальных утечек данных растет с каждым днем, — это бизнес, одержимый приватностью. Подумайте о юристах, работающих с конфиденциальными договорами, врачах, анализирующих истории болезней, или R&D-отделах корпораций, создающих прорывные технологии. Для них передача чувствительной информации в облачные API — это неприемлемый риск, как с точки зрения безопасности и законодательства, так и с точки зрения репутации. Локальный запуск предоставляет им стопроцентную гарантию того, что коммерческая тайна или персональные данные никогда не покинут защищенный внутренний контур компании.
Наконец, есть еще одна, не менее важная группа — пользователи «вне зоны доступа». Я говорю о людях, работающих в экспедициях, на удаленных объектах или просто в регионах с нестабильным и дорогим интернет-соединением. Для них доступ к облачным сервисам — это роскошь, а не данность. Локальный AI становится для них не вопросом удобства, а критически важной технологией, обеспечивающей доступ к современным инструментам в любых условиях.
Если вы узнали себя в одном из этих портретов или вам просто интересно, как обстоят дела в этой бурно развивающейся индустрии, эта статья — для вас. Давайте строить вашу персональную «AI-кухню».

Анатомия локального AI. Технологии, форматы и герои
Как так получилось, что огромные, многомиллиардные модели, которые еще вчера требовали мощностей целого дата-центра, теперь помещаются у нас под столом? Чтобы ответить на этот вопрос, нужно разобраться в анатомии этой локальной революции. Я проанализировал технологическую базу, лежащую в ее основе, и выделил три ключевых аспекта: магию сжатия, роль титанов из сообщества и скрытые архитектурные подводные камни, о которые спотыкаются многие новички.
Магия сжатия и формат GGUF
Начнем с главного. Исходные модели, которые рождаются в лабораториях Google или Meta, — это настоящие гиганты. Они весят сотни гигабайт и хранят свои параметры (веса) в высокоточных 16-битных форматах с плавающей точкой (FP16). Попытка загрузить такого монстра в память даже самой мощной потребительской видеокарты с 24 ГБ VRAM — это как пытаться залить воду из океана в аквариум.
Решением этой проблемы стала квантизация — ключевой метод «сжатия» модели, который лежит в основе всего локального AI. Чтобы объяснить эту концепцию, можно использовать аналогию из мира аудио. Представьте, что исходная модель в формате FP16 — это аудиозапись в студийном качестве FLAC. Она безупречна, но занимает колоссальный объем. Квантизация (например, до 4-битного представления) — это как грамотное сжатие этого трека в качественный MP3 с битрейтом 320 kbps. Да, какие-то тончайшие нюансы, которые услышит только профессиональный звукорежиссер на эталонном оборудовании, теряются. Но для 99% слушателей разницы нет никакой, а файл при этом весит в разы меньше. То же самое происходит и с моделью: мы немного жертвуем математической точностью весов, но получаем огромное снижение требований к памяти, почти не теряя в качестве ответов. С типами квантизации можно ознакомиться здесь.
Но просто сжать модель недостаточно. Нужно было создать универсальный «контейнер», который позволил бы этой похудевшей модели эффективно работать на гибриде из CPU и GPU, что является типичной конфигурацией для домашнего ПК. Этим стандартом де-факто стал формат GGUF (GPT-Generated Unified Format). Это не просто файл с весами модели. Это целый «загрузочный пакет», который содержит все необходимое: сами квантизованные веса, словарь токенизатора для преобразования текста в числа и обратно, а также важные метаданные о структуре и параметрах. Его архитектура спроектирована так, чтобы эффективно использовать как быструю видеопамять (VRAM), так и более медленную системную оперативную память (RAM), позволяя гибко распределять нагрузку.
Титаны сообщества
Проанализировав десятки репозиториев на Hugging Face, я понял одну важную вещь: вся эта экосистема живет и дышит благодаря труду энтузиастов. Вам, как конечному пользователю, не нужно быть экспертом по компиляции моделей или иметь доступ к кластеру из H100. Скорее всего, вы скачаете уже готовую, идеально оптимизированную GGUF-версию от таких контрибьюторов, как bartowski, которые проделывают колоссальную работу, мастерски «упаковывая» исходные модели в удобные для использования файлы.
А есть и целые команды, например Unsloth, которые идут еще дальше. Они не просто упаковывают модели, а используют продвинутый метод квантизации, чтобы до предела оптимизировать процессы обучения и инференса. Ключевая особенность Unsloth Dynamic 2.0 Quants заключается в «динамическом» подходе. Вместо того чтобы одинаково сжимать всю модель, Dynamic 2.0 анализирует каждый её слой и интеллектуально подбирает для него наилучший способ и уровень квантизации. Какие-то слои могут быть сжаты сильнее, а более важные для производительности модели слои сохраняют более высокую точность. Это и есть настоящий дух open-source в действии, когда сообщество делает передовые технологии доступными для всех.
Скрытые узкие места
Однако, несмотря на всю магию оптимизации, существуют неочевидные факторы, которые могут стать тем самым «бутылочным горлышком» для вашей системы. Главный из них — длина контекста (или размер контекстного окна). Представьте, что память вашей видеокарты (VRAM) — это площадь вашего рабочего стола. Сама модель — это набор папок с документами на нем. А контекст — это количество папок, которые вы держите открытыми одновременно для работы. Чем больше контекст (чем длиннее ваша беседа с чат-ботом), тем больше «открытых папок» и тем больше места они занимают на столе, то есть в VRAM.
Это приводит к тому, что производительность локальных LLM часто упирается не в чистую вычислительную мощность GPU, а в пропускную способность и объем памяти. Именно поэтому для эффективной работы GGUF-моделей так важна общая сбалансированность системы. Быстрая оперативная память (DDR5 будет заметно лучше DDR4) и многоядерный CPU становятся критически важны, поскольку часть нагрузки по обработке данных неизбежно ложится и на них, особенно когда модель не помещается в VRAM целиком и начинает использовать системную память.

Собираем свой AI-воркстейшн
Мы разобрались в теории, поняли, что VRAM — это новая нефть, а сбалансированность системы — ключ к успеху. Теперь перейдем к самой волнующей части — сборке «железа». Я считаю, что выбор компонентов для локального AI — это не просто гонка за самыми высокими частотами и терафлопсами, а тонкий инженерный расчет, в котором объем видеопамяти часто оказывается важнее чистой скорости. Давайте разберем актуальные сборки, отталкиваясь от разных бюджетов и целей.
Прежде чем мы перейдем к конкретным моделям видеокарт, давайте зафиксируем главный принцип: при сборке AI-воркстейшна главная валюта — это не терафлопсы, а гигабайты видеопамяти (VRAM). Именно объем VRAM определяет, модели какого размера вы сможете запускать комфортно, а скорость GPU влияет на то, как быстро вы будете получать ответ (tokens per second).
Уровень 1: "Экосистема Apple" — Mac с M2/M3/M4 (24 ГБ+ объединенной памяти)
Для кого: Новички и профессионалы, уже работающие в экосистеме Apple. Это, без преувеличения, идеальный старт «из коробки». Главное преимущество Mac на чипах Apple Silicon — унифицированная память. CPU и GPU имеют прямой доступ к общему пулу сверхбыстрой RAM, что стирает традиционные «узкие места». Благодаря этому и фреймворку MLX, оптимизированному под эту архитектуру, вы получаете невероятно плавный и беспроблемный опыт. Вам не нужно возиться с драйверами и настройками — все просто работает. Судя по тестам сообщества, машины с 24 ГБ и более объединенной памяти отлично справляются с большинством популярных моделей.
Уровень 2: "Народный вход" — Nvidia GeForce RTX 3060 12GB
Для кого: Энтузиасты с ограниченным бюджетом. Эта видеокарта — настоящий феномен. Несмотря на свой возраст, она остается лучшим билетом в мир локального AI благодаря своим 12 ГБ VRAM. На вторичном рынке ее можно найти в диапазоне 17-20 тысяч рублей, что дает ей лучшее соотношение «цена/гигабайт видеопамяти». Этого объема достаточно для комфортной работы с моделями размером до 13 миллиардов параметров, что покрывает огромный пласт задач. Я сам начинал с такой и, как и многие в сообществе, считаю ее более разумной покупкой для AI, чем, например, более новую RTX 5060, у которой всего 8 ГБ памяти на борту. Также, если не хочется заморачиваться с б/у вариантами, можно рассмотреть RTX 5060 с 16GB VRAM, бюджет 45-50 тысяч рублей.
Уровень 3: "Золотой стандарт энтузиаста" — Nvidia GeForce RTX 3090 / 3090 Ti 24GB
Для кого: Серьезные любители и исследователи, ищущие идеальный баланс цены и возможностей. Вот мы и подошли к самому интересному варианту. RTX 3090 — это настоящая «рабочая лошадка» для локального AI. Да, в играх она уступает новым поколениям, но ее 24 ГБ VRAM — это тот самый «золотой стандарт», который открывает дверь в мир больших моделей (вплоть до 70B в хорошей квантизации). За 70-80 тысяч рублей на вторичном рынке вы получаете карту, которая, как справедливо отмечают пользователи на Reddit, «прослужит еще 5+ лет», позволяя экспериментировать с тяжелыми моделями и длинными контекстами без компромиссов.
Уровень 4: "За пределами одной карты" — Современные GPU и кастомные риги
Для кого: Энтузиасты, которые не приемлют компромиссов. Конечно, современные карты вроде RTX 5070 Ti (16 ГБ) или флагманской RTX 5090 (32 ГБ) предлагают колоссальную производительность. Но, как я уже говорил, для LLM объем VRAM часто важнее скорости. Впрочем, когда речь идет о топовых сборках, важен именно баланс. Судя по отчетам энтузиастов, система с 96 ГБ быстрой оперативной памяти и RTX 5080 способна выдавать 25 токенов в секунду на модели Qwen3-Coder 30B с гигантским контекстом в 256 тысяч токенов. Это еще раз доказывает, что мощный GPU должен быть подкреплен не менее мощными CPU и RAM. Также можно построить риг из нескольких видеокарт, например такой или такой.
Уровень 5: "Коммерческий сектор" — NVIDIA H100/H200
Для кого: Компании и исследовательские центры. Это уже другая лига. Nvidia H100 и H200 — это золотой стандарт для обучения и инференса в дата-центрах. С 80/141 ГБ сверхбыстрой памяти HBM3, они являются выбором №1 для OpenAI, Anthropic и всех крупных облачных провайдеров. Упоминаю я их здесь лишь для того, чтобы показать масштаб: то, что мы делаем локально, — это миниатюрная копия процессов, идущих в этих вычислительных монстрах.
Уровень 6: "Новые архитектуры" — Groq и Cerebras
Для кого: Взгляд в будущее AI-инференса. В последнее время я все чаще вижу, как доминированию GPU бросают вызов компании с принципиально иными архитектурами. Groq (не путайте с Grok от Илона Маска) со своим процессором LPU (Language Processing Unit) был создан для одной цели — выполнять языковые модели с минимально возможной задержкой. Его потоковая архитектура, похожая на идеально отлаженный конвейер, обеспечивает рекордную скорость в токенах/сек, что идеально для чат-ботов и real-time приложений. Cerebras, в свою очередь, пошла еще дальше, создав WSE (Wafer-Scale Engine) — гигантский чип размером с целую кремниевую пластину. Это устраняет «узкие места» GPU-кластеров, так как огромная модель может поместиться на один-единственный чип. Пока это в основном решения для обучения фундаментальных моделей, но они наглядно показывают, что будущее AI-железа может быть очень разнообразным.
По данным Openrouter при использовании модели qwen3-32b, провайдер Groq обеспечивает скорость более 600 ток/сек, Cerebras более 1400 ток/сек, при привычной скорости 50-80 ток/сек.

Выбор ПО. От простого клика до полного контроля
Итак, наша «AI-кухня» собрана, железо гудит в предвкушении. Теперь пришло время выбрать главный инструмент — программное обеспечение, которое и будет «готовить» наши нейросетевые блюда. Проанализировав текущее состояние экосистемы, я могу с уверенностью сказать: в 2025 году выбор стал невероятно богатым. Прошли те времена, когда для запуска модели нужно было вручную компилировать код и разбираться в десятках зависимостей. Сегодня есть инструменты на любой вкус — от элегантных приложений, где все делается одним кликом, до мощных консольных утилит для полного контроля. Ваш выбор будет зависеть лишь от того, насколько глубоко вы хотите погрузиться в процесс.
Для новичков и быстрого старта (GUI)
Если вы хотите получить результат здесь и сейчас, не вдаваясь в технические дебри, ваш выбор — приложения с графическим интерфейсом (GUI). Они превращают сложный процесс в интуитивно понятный и дружелюбный.
LM Studio: Я часто рекомендую его своим знакомым, потому что это, по сути, «браузер и менеджер для LLM». Он идеален для нетехнических пользователей. Внутри вы найдете удобный поиск по моделям с Hugging Face, сможете скачать понравившуюся в один клик и тут же запустить ее в окне чата. Но его главная сила — встроенный локальный API-сервер, совместимый с API OpenAI. Это позволяет легко интегрировать локальную модель в ваши собственные скрипты или сторонние приложения. А еще LM Studio — умная программа: она определяет вашу видеокарту и при выборе модели дает прямые подсказки, поместится ли модель целиком в быструю видеопамять.
Jan: Этот инструмент я бы назвал главным идеологическим конкурентом LM Studio. Он предлагает схожий функционал, но с одним ключевым отличием — Jan является проектом с полностью открытым исходным кодом. Для тех, кто ценит прозрачность, возможность заглянуть «под капот» и поддержать open-source сообщество, это будет решающим фактором.
GPT4All: Этот проект выбирает другой подход. Вместо того чтобы дать вам доступ ко всем моделям мира, его команда предлагает тщательно подобранный и протестированный список моделей, которые гарантированно хорошо работают на обычном потребительском «железе». Если вы не хотите тратить время на чтение обзоров и сравнение квантизаций, а просто ищете готовое и надежное решение, GPT4All — отличный выбор.
Для разработчиков и продвинутых пользователей (CLI)
Если вы разработчик, исследователь или просто любите держать все под контролем, ваш путь лежит в мир инструментов командной строки (CLI).
Ollama: Я считаю, что этот инструмент произвел настоящую революцию в простоте развертывания. Всего одна команда в терминале —
ollama run llama3— и Ollama сама скачает, настроит и запустит последнюю версию Llama 3, подняв локальный API. Это идеальное решение для разработчиков, которым нужно быстро интегрировать LLM в свой рабочий процесс, не отвлекаясь на настройку окружения. В июле 2025 года разработчики выпустили официальное десктопное приложение для macOS и Windows.Llama.cpp: Это не просто приложение, это фундаментальная технология. Llama.cpp — это высокопроизводительная библиотека, написанная на C/C++, которая служит «движком» для многих других программ, включая LM Studio и Ollama. Работа с ней напрямую дает максимальную производительность и гибкость. Если вам нужно выжать из своего железа все соки, настроить каждый параметр инференса и добиться минимальной задержки — ваш выбор однозначно Llama.cpp.
text-generation-webui (Oobabooga): Если Llama.cpp — это двигатель, то Oobabooga — это приборная панель гоночного болида. Это мощнейший веб-интерфейс, который предоставляет доступ к сотням настроек для экспериментов, чата и даже дообучения моделей. Одна из его киллер-фич — возможность гибко распределять слои модели между видеопамятью, оперативной памятью и даже диском, что позволяет запускать гигантские модели, которые, казалось бы, никак не могут поместиться в вашу систему.
Чтобы вам было проще ориентироваться в этом многообразии, я свел ключевые характеристики в одну простую таблицу:


Ваш первый запуск: модели-рекомендации
Итак, вы выбрали свой инструмент из списка выше — будь то удобный LM Studio или спартанский Ollama. Теперь самый волнующий момент: что же запустить первым? Мир open-source моделей огромен, и чтобы вы не растерялись, вот мой личный шорт-лист — три модели, которые отлично иллюстрируют возможности локального AI и хорошо работают на разном "железе".
-
Qwen3-4B: Две 4-миллиардные модели от Alibaba с одинаковой архитектурой, но разным подходом.
Instruct-2507 — это "быстрый и послушный универсал", заточенный на четкое следование инструкциям и лаконичные ответы. Он не показывает процесс рассуждения, а сразу выдает результат, что идеально для общих задач.
Thinking-2507 — "вдумчивый решатель проблем". Эта версия перед ответом подробно расписывает свою логическую цепочку, делая процесс прозрачным. Она превосходно подходит для программирования, математики и сложных аналитических задач, где важен ход рассуждений.
Llama-3.1-8B-Instruct:. Это прекрасно сбалансированный универсал, который отлично справляется с широким кругом задач: от ответов на вопросы и саммаризации текста до творческой работы и ведения сложных диалогов. Благодаря качественной доработке с участием людей (RLHF), модель хорошо понимает пользовательские запросы и генерирует качественный контент.
Gemma-3n (E2B/E4B):. Семейство моделей, созданное на основе технологий Gemini и специально оптимизированное для работы на устройствах с ограниченными ресурсами, например, на ноутбуках. Обозначения E2B и E4B указывают на "эффективный" размер в 2 и 4 миллиарда параметров, который достигается за счет специальной архитектуры MatFormer. Изначально модели мультимодальны (могут работать с текстом, изображениями и аудио), но популярные GGUF-версии пока ограничены текстом. Это отличный выбор для не самого мощного "железа" и экспериментов.

Инструментарий и сообщество. Ваши помощники
Вы выбрали железо, определились с программным обеспечением, выбрали модель и вот-вот готовы сделать первый запуск. На этом этапе путь в мир локального AI может показаться сложным и немного одиноким. Но спешу вас заверить: вы не одни в этом путешествии. За последние годы вокруг этой технологии выросла целая экосистема ресурсов, инструментов и, что самое главное, людей, готовых помочь. Давайте я покажу вам карту этой экосистемы.
Где искать помощь и единомышленников
Если бы мне нужно было назвать одно-единственное место, которое является сердцем и мозгом всего движения, я бы без колебаний выбрал сабреддит r/LocalLLaMA. Проанализировав сотни тредов, я могу с уверенностью сказать, что это не просто форум. Это главный «хаб», нервный центр сообщества. Именно здесь появляются самые свежие новости о выходе новых моделей, публикуются подробные гайды по настройке сложного софта, выкладываются результаты тестов производительности на разном железе. Если вы столкнулись с проблемой, которая кажется неразрешимой, будь то загадочная ошибка при компиляции или неожиданно низкая скорость генерации, просто задайте вопрос. С высокой вероятностью кто-то уже сталкивался с чем-то подобным и готов поделиться решением.
Навигаторы в мире инструментов
Экосистема локального AI растет так быстро, что количество программ, фреймворков и утилит может вызвать головокружение даже у опытного специалиста. Чтобы не утонуть в этом многообразии, сообщество придумало элегантное решение — курируемые списки, известные как "Awesome Lists". Я настоятельно рекомендую добавить в закладки такие репозитории, как awesome-local-llms или Awesome-local-LLM. Считайте их вашим компасом в мире ПО для локального AI. Эти списки постоянно обновляются и содержат ссылки на все — от GUI-лаунчеров до нишевых библиотек, помогая быстро найти нужный инструмент и не тратить часы на самостоятельные поиски.
Практические помощники
Помимо глобальных ресурсов, существует и множество мелких, но невероятно полезных утилит, которые упрощают повседневную жизнь AI-энтузиаста.
Калькуляторы VRAM: Это ваш главный помощник на этапе выбора модели. Прежде чем скачивать файл весом в десятки гигабайт, просто зайдите на один из онлайн-калькуляторов (например, на этот или этот). Введя параметры модели (количество параметров, тип квантизации), вы мгновенно получите оценку необходимого объема видеопамяти. Это избавляет от досадной ситуации, когда вы качали модель только для того, чтобы понять, что она не помещается в вашу видеокарту.
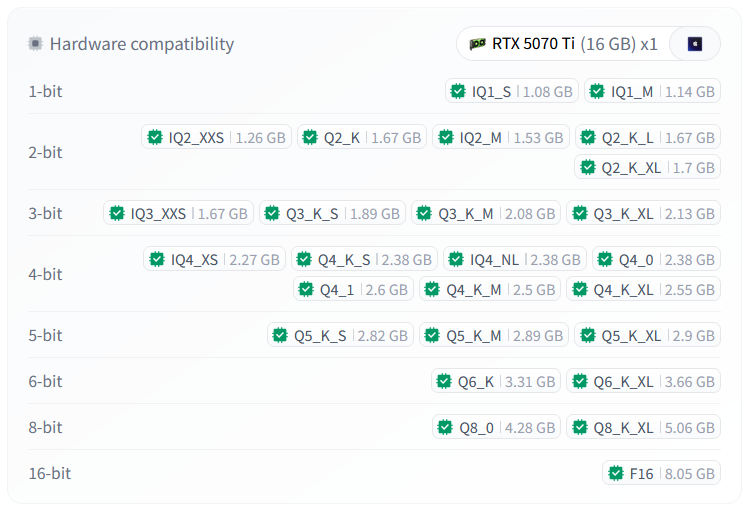
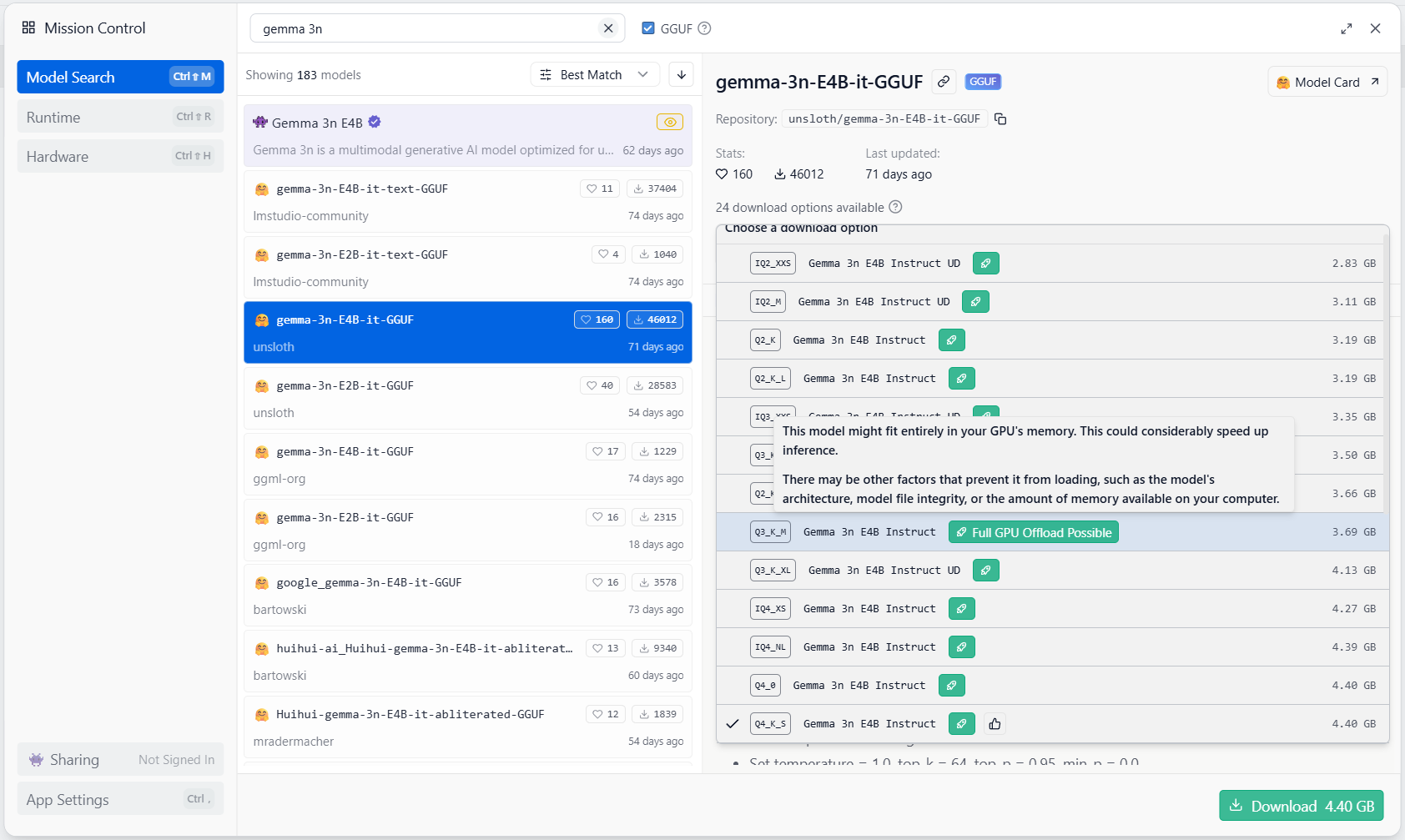
Подсказки на Hugging Face: Сообщество и разработчики моделей делают все, чтобы избавить нас от догадок. На страницах многих популярных моделей на Hugging Face есть специальный блок «Hardware compatibility». Он в явном виде показывает, какая версия квантизации (например, Q4_K_M) для какого объема VRAM (8GB, 12GB, 24GB) подходит лучше всего.
Интерактивные гиды в ПО: Софт для запуска, о котором мы говорили в предыдущем разделе, идет еще дальше. Тот же LM Studio автоматически определяет вашу GPU и при выборе модели из списка дает прямые и понятные подсказки. Увидев надпись «Full GPU Offload Possible», вы можете быть на 100% уверены, что эта модель будет работать максимально быстро, полностью загрузившись в быструю видеопамять. Это маленький, но очень важный штрих, который делает технологию доступнее для всех.

Локально или по API: Честное сравнение
Мы собрали железо, выбрали софт, нашли единомышленников и вооружились полезными утилитами. Кажется, все части головоломки на месте. Но прежде чем мы заглянем в будущее, нужно остановиться и провести честный, безэмоциональный анализ. Настало время ответить на главный вопрос: в какой ситуации наша с таким трудом собранная «AI-кухня» действительно лучше, чем заказ еды из ресторана в виде облачного API?
Я провел много времени, работая как с локальными моделями, так и с различными API, и пришел к выводу, что однозначного ответа «что лучше?» не существует. Это всегда компромисс, взвешивание приоритетов. Чтобы помочь вам принять собственное, осознанное решение, я свел все ключевые различия в единую сравнительную таблицу. В ней мы столкнем лбами три подхода: наш локальный запуск, стандартное облачное API от гигантов вроде Google (Gemini 2.5 Pro) и новое поколение узкоспециализированных API на примере Groq.

Как видите, выбор сводится к простому вопросу: что для вас важнее? Если ваш приоритет — абсолютный суверенитет над данными, полная предсказуемость расходов и безграничная свобода для экспериментов, то локальный запуск — ваш единственный путь. Если же вам нужен быстрый доступ к самой мощной модели здесь и сейчас, без первоначальных вложений и головной боли с настройкой, то облачные API остаются вне конкуренции. А если ваша задача требует молниеносной реакции, например, в real-time приложениях, то на горизонте появляются новые, мощные игроки вроде Groq или Cerebras.

Следующий рубеж. AI в вашем кармане
Мы провели честное сравнение, разложили по полочкам все "за" и "против", сфокусировавшись на наших мощных десктопных системах. Но революция локального AI не собирается останавливаться под нашими столами. Ее финальная, самая амбициозная цель — стать по-настоящему персональной, а значит — мобильной. Проанализировав текущие тренды, я вижу, как AI приходит в наши смартфоны двумя совершенно разными, почти параллельными путями.
Встроенный AI от производителей
Гиганты индустрии, такие как Apple и Google, прекрасно понимают, куда дует ветер. Они уже начали активно интегрировать сверхкомпактные, но мощные проприетарные модели прямо в свои операционные системы. Ярчайшие примеры — это Apple Intelligence, представленная для последних моделей iPhone, и Gemini Nano, работающая на флагманских Google Pixel и Samsung Galaxy.
Как это работает? По сути, это закрытые, тщательно охраняемые экосистемы. Внутри них трудятся специально обученные и до предела оптимизированные модели размером около 3 миллиардов параметров. Их задача — не вести с вами философские беседы, а выполнять конкретные системные функции: предлагать умные ответы в мессенджерах, мгновенно транскрибировать аудиозаписи, сортировать уведомления по важности или улучшать фотографии. Здесь стоит учесть, что компании четко разделяют, какие функции работают локально, а какие требуют подключения к облаку.
Почему именно 3 миллиарда параметров? Потому что это текущий технологический 'sweet spot', позволяющий модели быть достаточно умной для системных задач и при этом работать в жестких рамках энергопотребления мобильного чипа, не превращая телефон в кипятильник.
Я бы сравнил это со встроенным навигатором в современном автомобиле. Он невероятно удобен, идеально интегрирован в приборную панель, работает без каких-либо настроек и не требует подписки. Но вы не можете заменить его на карты другого производителя, добавить свои кастомные маршруты или расширить его функционал плагинами. Это удобно, бесшовно и работает для всех. Но что, если вы хотите большего контроля?
DIY-AI на смартфонах
Именно здесь начинается самое интересное. Параллельно с корпоративными «садами» существует и бурно развивается «дикий запад» — процветающее движение энтузиастов, которые находят способы запускать открытые модели на своих телефонах. Это путь для тех, кто хочет полного контроля и не боится экспериментов.
Это стало возможным благодаря появлению специализированных приложений. Я обнаружил, что такие проекты, как LLM Farm или PocketPal, открывают дверь в этот удивительный мир. С их помощью на современных смартфонах, оснащенных мощными нейронными движками, можно запускать открытые модели с 2-4 миллиардами параметров. Речь идет о квантизованных версиях популярных моделей, таких как Qwen-3, или Gemma-3n. Судя по отчетам в сообществе, результаты впечатляют: некоторые пользователи добиваются скорости генерации около 20 токенов в секунду на iPhone.
Для меня это очень похоже на установку продвинутой кастомной прошивки на Android-смартфон. Да, это требует определенных технических навыков, терпения и готовности к тому, что что-то может пойти не так. Но в награду вы получаете доступ к функциям, недоступным «из коробки», и полный контроль над системой. Это путь для тех, кто хочет не просто пользоваться AI, а владеть им. Превратить свой телефон из простого клиента для облачных сервисов в полностью автономный, суверенный интеллектуальный инструмент.

Песочница для будущего
Проделав весь этот путь — от выбора железа до запуска модели на собственном смартфоне, — я хочу, чтобы вы на секунду остановились и осознали: то, что стоит у вас под столом, — это не просто мощный компьютер. Это миниатюрная, персональная версия исследовательской лаборатории OpenAI или Google DeepMind. Именно так я вижу суть локального AI. Это не просто технология, это самая большая, доступная и захватывающая «песочница» для инноваций со времен появления массового интернета. Это возможность для каждого энтузиаста, разработчика и исследователя напрямую прикоснуться к технологиям, которые прямо сейчас меняют мир, и начать экспериментировать без оглядки на API-лимиты, бюджеты и корпоративные дорожные карты.
История технологий много раз доказывала: настоящие прорывы часто случаются не в стерильных лабораториях мегакорпораций, а в тех самых «гаражных» условиях, где страсть и любопытство важнее многомиллионных инвестиций. Следующий «ChatGPT» может быть создан не командой из сотен инженеров, а одним студентом в общежитии, который от скуки дообучил локальную модель для решения уникальной, никем ранее не замеченной задачи. Локальный AI возвращает эту возможность в наши руки. Он демократизирует доступ к самому мощному инструменту нашего времени.
В этой статье я постарался дать вам карту и компас: мы разобрали актуальное «железо», изучили программное обеспечение на любой вкус и нашли, где искать помощи у единомышленников. Теперь ваш ход. Начните экспериментировать. Скачайте свою первую модель. Попробуйте заставить ее написать код, стихотворение или план захвата мира. Сломайте что-нибудь. Почините. Создайте что-то новое, что-то свое. Возможности, которые открываются перед вами, ограничены только вашей фантазией.
Облачные гиганты строят величественные «соборы» искусственного интеллекта, доступ в которые строго регламентирован. Сообщество локального AI дает каждому из нас кирпичи и мастерок, чтобы построить свой собственный.
Начните строить сегодня и оставайтесь любопытными.
Взгляд инди-хакера на AI и разработку: глубокое погружение в языковые модели, гаджеты и self-hosting через практический опыт в моем телеграм канале.
Комментарии (24)

Antra
09.09.2025 07:59Отлично!
Не смотрели ли ли вы на новую NVIDIA RTX PRO 6000 Blackwell with 96GB? Не для дома, конечно (~$10K, насколько я понимаю), но вроде ощутимо дешевле всяких H100, ADA 6000 с такой же памятью.
Да и какие-нибудь 4 x 4090 24GB не дешевле выйдут (с накладными расходами на распределение слоев по картам, обмен между картами).

xonika9 Автор
09.09.2025 07:59Да, PRO 6000 может быть хорошим, хоть и дорогим, решением, когда нужен максимальный объем VRAM в одной карте без головной боли с multi-GPU.
Потребление в 600W решает. Для рига из 4-6x 3090/4090/5090 придется покупать несколько киловаттных блоков питания, делать спец разводку, строить корпус и даже делать апгрейд своей электросети. PRO 6000 меньше потребляет, меньше греется, меньше шумит. Не придется придумывать охлаждение.
Как вариант, который пользуется популярностью на реддите и ютубе, можно рассмотреть Mac Studio с 512GB памяти. По цене будет также ~$10K. На такой можно и Deepseek с квантизацией запустить. А можно построить кластер из нескольких - https://www.youtube.com/watch?v=Ju0ndy2kwlw
https://www.apple.com/shop/buy-mac/mac-studio/apple-m3-ultra-with-28-core-cpu-60-core-gpu-32-core-neural-engine-96gb-memory-1tb
Antra
09.09.2025 07:59А по скорости сравнимо или ощутимо (в разы) все-таки медленнее?
Так-то, конечно, я предпочитаю универсальные решения (чтобы не только для ИИ использовать)
xonika9 Автор
09.09.2025 07:59Я думаю, что Mac Studio будет значительно медленнее. PRO 6000 все же заточена под вычислительные задачи, а Mac Studio просто дает хорошее соотношение GB/$ и удобство.
Если главный критерий – это максимальная сырая производительность для тренировки и быстрого инференса очень больших моделей, особенно с учетом дообучения, то NVIDIA является явным победителем. Если же важны такие аспекты, как доступность, низкое энергопотребление, тишина, компактность и возможность запускать большие модели для инференса по более доступной цене (особенно если речь идет о моделях до 130B), то Mac Studio может быть отличным выбором, несмотря на более низкую скорость.
Можете почитать обсуждение - https://www.reddit.com/r/LocalLLaMA/comments/1jzezim/mac_studio_vs_nvidia_gpus_pound_for_pound/
Вот бенчмарк Mac Studio с 96GB - https://www.reddit.com/r/LocalLLaMA/comments/1kvd0jr/m3_ultra_mac_studio_benchmarks_96gb_vram_60_gpu/.
Там же можете поискать бенчмарки разных GPU.

programania
09.09.2025 07:59В статье не сказано о MOE моделях, а за ними будущее для локального применения:
openai_gpt-oss-120b-MXFP4.gguf - 14 t/s, 40 символов в сек.
при этом видеокарта вообще не используется,
используется 1 файл llama-server.exe в 6 мб без всяких dll.Ещё преимущество локального запуска -
контроль и управление процессом из своей программы.
holgw
09.09.2025 07:59+, я не понимаю почему об этом везде не трубят, MoE реально перевернула игру, сделав локальные модели гораздо более юзабельными. GGUF модели без MoE для реальных задач слабо применимы, потому что быстрее руками сделать, чем ждать инференса на скорости 2-3 t/s. А вот 10-17 t/s, которые дают модели с MoE -- это уже то, с чем можно работать.
xonika9 Автор
09.09.2025 07:59Спасибо, изучу этот момент. А какие модели посоветуете попробовать?
holgw
09.09.2025 07:59Попробуйте линейку Qwen3 посмотреть. Для моих задач хорошо себя показала Qwen3-Coder-30B.

Neikist
09.09.2025 07:59Однозначно. Благодаря MoE использую 30b модель (qwen3-coder) даже просто для автокомплита, ибо скорость генерации выдает автокомплит за секунду. Не MoE модели использовал максимум 14b для этих целей (поскольку она влезала в мои 16 гигов 4080 super).
Отлично работают крупные модели даже просто на CPU. Для локального домашнего применения за ними 100% будущее. Ибо все остальные варианты поднимают ценники железа ближе к миллиону для адекватного домашнего запуска крупных моделей.
Antra
09.09.2025 07:59Интересно... Какую именно модель вы для автокомплита используете, с какими настройками?

Я кучу перепробовал. Для кодинга такой маленький qwen3-coder вообще не зашел, а для автокомплита devstral больше понравился.
Может с настройками поиграться надо (K/V cahce quantization какой-нибудь..)
.P.S. Очень понравился gpt-oss-20b (оригинальный MXPF4) для работы с MCP (слазить куда-то в БД или по API). И понимает, куда полезть, какой tool использовать, и финальный результат хорошо выдает.
Neikist
09.09.2025 07:59devstral не MoE, как я понимаю. Для автокомплита слишком медленный будет (ибо в память видеокарты не влезет в моем случае вместе с контекстом). Я для автокомплита qwen3-coder:30b-a3b Q4_K_M использую, температура 0.3, качество автодополнения устраивает. Кстати, надо бы на q6 поменять хотя бы.
З.Ы. А если чтобы прям полноценно код писало - то в своем основном стеке не использую нейронки для этого. Использую их для этого только когда пишу на чем то малознакомом. Питон, nix, баш, etc.Antra
09.09.2025 07:59qwen3-coder-30b-a3b-instruct@q4_k_m? А остальные параметры какие?
Скажем, context length? Может тут моя ошибка была, для автокомплита и 8К за глаза хватит. (или даже 4К)? Flash attention? Ставить ли принудительно Cache Quantization Type?
Я вообще не программист, для меня все малознакомое :)К примеру, я бы сроду не смог в FastAPI сделать, чтобы по по завершении определенного эндпойнта (cleanup директорий, таблиц БД...) uvicorn бы завершился, чтобы заново стартовать и все переинициализировать. Только пришлось дополнительно ее пнуть, чтобы убрала лишние ругательства из логов при рестарте.
В таких делах мне OpenRouter z-ai/glm-4.5-air:free в RooCode офигенно помогает. Разумеется, потом смотрю, что ИИ наваял, какие-то мелочи проще самому поправить. Заодно учусь.



vrangel
09.09.2025 07:59Есть ли смысл в старых картах Tesla? Например, Tesla V100? Ищу приемлемое по цене решение для транскрибации записей телефонных разговорв колл-центра.

Applechina
09.09.2025 07:59В выборе локальная модель vs внешний сервис важен вопрос ИБ, а при его оценке, кажется, стоит сравнивать не безопасность в вакууме, а реально достижимый уровень безопасности с учетом возможностей компании. Фактическая стоимость рисков внешнего сервиса может оказаться, ниже, хотя абс. уровень безопасности, конечно, ниже.


{kind=link}
{kind=link}
VitaminND
Спасибо! А чем можно воспользоваться, чтобы указать LLM каталог проекта и описывать, какие изменения надо сделать, и чтобы этот LLM после согласования правил там файлы? Типа локальный аналог Warp?
holgw
Посмотрите на aider -- запускается в терминале, умеет парсить вывод консольных команд (git diff, например), умеет работать с файловой системой.
Вообще, агентных редакторов много разных, первое что вспомнил: roocode (решение в виде плагина для VS Code), void (самостоятельное приложение на базе VS Code).
Но есть подводные камни. Мощности локальных моделей с трудом хватает для агентного редактирования. Void почему-то вообще отказывается читать файлы при подключении к локальной модели (известный баг, никак не пофиксят), что делает его неюзабельным. Aider более-менее работает, но результат непредсказуемый -- то файл не туда закинет, то без без причин удалит существующий файл. Благо есть возможность откатить последние изменения одной командой, но все равно требуется постоянно следить за результатом.
xonika9 Автор
Если речь про написание кода, можно попробовать:
1. Aider, он работает в терминале. Там есть интеграция с Ollama или OpenAI-подобными API. https://aider.chat/docs/llms.html
2. RooCode или KiloCode, они работают в VSCode. Там в провайдерах можно указать Ollama или LmStudio.